АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Листинг 8.6. Формат представления массива каталогов
смещение размер описание
-------- ------ --------
0 4 inode; Ссылка на inode
4 2 rec_len; Длина данной записи
6 1 name_len; Длина имени файла
7 1 file_type; Тип файла
8... name; Имя файла
При удалении файла операционная система находит соответствующую запись в каталоге, обнуляет поле inode и увеличивает размер предшествующей записи (поле rec_len) на величину удаляемой записи. Таким образом, предшествующая запись "поглощает" удаленную. Хотя имя файла в течение некоторого времени остается нетронутым, ссылка на соответствующий ему индексный дескриптор (inode) оказывается уничтоженной. Это создает проблему, так как теперь придется разбираться, какому файлу принадлежит обнаруженное имя.
В самом индексном дескрипторе при удалении файла тоже происходят большие изменения. Количество ссылок (i_links_count) обнуляется и обновляется поле последнего удаления (i_dtime). Все блоки, принадлежащие файлу, в карте свободного пространства (block bitmap) помечаются как неиспользуемые, после чего данный inode также освобождается (обновляется inode bitmap).
Техника восстановления удаленных файлов
В ext2fs полное восстановление файлов невозможно, даже если эти файлы были только что удалены. В этом отношении данная файловая система проигрывает как FAT, так и NTFS. Как минимум, теряется имя файла. Точнее говоря, теряется связь имен файлов с их содержимым. При удалении небольшого количества хорошо известных файлов эта проблема остается решаемой. Однако ситуация серьезно осложняется, если вы удалили несколько служебных подкаталогов, в которых никогда ранее не заглядывали.
Достаточно часто индексные дескрипторы назначаются в том же порядке, в котором создаются записи в таблице каталогов. Благодаря наличию расширений имен файлов (.c,.gz,.mpg, и т.д.) количество возможных комбинаций соответствий обычно оказывается сравнительно небольшим. Тем не менее, восстановить удаленный корневой каталог в автоматическом режиме никому не удастся (а вот NTFS с этим справляется без труда).
В целом, стратегия восстановления выглядит приблизительно так: сканируем таблицу индексных дескрипторов (inode table) и отбираем все записи, чье поле i_links_count равно нулю. Сортируем их по дате удаления, чтобы файлы, удаленные последними, оказались в верхних позициях списка. Как вариант, если вы помните примерное время удаления файла, можно просто наложить фильтр. Если соответствующие индексные дескрипторы еще не затерты вновь создаваемыми файлами, извлекаем список прямых/косвенных блоков и записываем их в дамп, корректируя его размер с учетом "логического" размера файла, за который отвечает поле i_size.
Восстановление удаленных файлов с помощью редактора Lde
Откройте редактируемый раздел или его файловую копию с помощью команд lde my_dump или lde /dev/sdb1. Редактор автоматически определяет тип файловой системы (в данном случае — ext2fs) и предлагает нажать любую клавишу для продолжения. Lde автоматически переключается в режим отображения суперблока и предлагает нажать клавишу <I> для перехода в режим inode или клавишу <В> — для перехода в блочный режим (block-mode). Нажмите клавишу <I>, и вы окажетесь в первом индексном дескрипторе, описывающем корневой каталог. Нажатие клавиши <Page Down> перемещает нас к следующему inode, а нажатие клавиши <Page Up>, — соответственно, к предыдущему. Пролистываем список индексных дескрипторов вниз, обращая внимание на поле LINKS. У удаленных файлов это поле равно нулю, и тогда поле DELETION TIME содержит время последнего удаления. Обнаружив подходящий inode по запомненному времени удаления, перемещаем курсор к первому блоку в списке DIRECT BLOCKS (где он должен находиться по умолчанию) и нажимаем клавишу <F2>. В появившемся меню выбираем пункт Block mode, viewing block under cursor (или сразу нажимаем клавиатурную комбинацию <Shift>+<B>). Редактор перемещается на первый блок удаленного файла. Просматривая его содержимое в шестнадцатеричном режиме, пытаемся определить, тот ли это файл, который требуется восстановить. Если вы нашли именно тот файл, который намеревались восстановить, нажмите для его восстановления клавиатурную комбинацию <Shift>+<R>, затем — клавишу <R>, и введите имя файла, в который требуется восстановить дамп. Чтобы вернуться к просмотру следующего inode, нажмите клавишу <I>.
Можно восстанавливать файлы и по их содержимому. Например, предположим, что нам известно, что удаленный файл содержит строку hello, world. Нажимаем <f>, затем — клавишу <A> (Search all block). Этим мы заставляем редактор искать ссылки на все блоки, в том числе и удаленные. Как вариант, можно запустить редактор с ключом --all. Но, так или иначе, затем мы нажимаем клавишу <В>, и, когда редактор перейдет в блочный режим, нажимаем клавишу </> и вводим искомую строку в ASCII. Находим нужный блок. Прокручивая его вверх и вниз, убеждаемся, что он действительно принадлежит тому самому файлу. Если это так, нажимаем <Ctrl>+<R>, давая редактору указание просматривать все индексные дескрипторы, содержащие ссылку на этот блок. Номер текущего найденного inode отображается в нижней части экрана.
Внимание!
Номер текущего найденного inode отображается именно в нижней части экрана. В верхней части отображается номер последнего просмотренного inode в режиме inode.
Переходим в режим inode нажатием клавиши <I>, нажимаем клавишу <#> и вводим номер inode, который требуется просмотреть. Если дата удаления более или менее соответствует действительности, нажимаем <Shift>+<R>/<R> для сброса файла на диск. Если нет — возвращаемся в блочный режим и продолжаем поиск.
В сложных случаях, когда список прямых и/или косвенных блоков разрушен, восстанавливаемый файл приходится собирать буквально по кусочкам, основываясь на его содержимом и частично — на стратегии выделения свободного пространства файловой системой. В этом нам поможет клавиша <w>, дающая указание дописать текущий блок к файлу-дампу. В процессе восстановления мы просто перебираем все свободные блоки один за другим (редактор помечает их строкой NOT USED) и, обнаружив подходящий, дописываем в файл. Конечно, таким образом невозможно восстановить сильно фрагментированный двоичный файл, но вот восстановление листинга программы — вполне реалистичная задача.
На основании вышесказанного можно сделать вывод о том, что ручное восстановление файлов с помощью lde крайне непроизводительно и трудоемко. Однако при этом данный подход является наиболее "прозрачным" и надежным. Что касается восстановления оригинальных имен файлов, то эту операцию лучше всего осуществлять с помощью отладчика файловой системы debugfs.
Восстановление с помощью отладчика файловой системы debugfs
Загружаем в отладчик редактируемый раздел или его копию. Сделать это можно с помощью команд debugfs /dev/sdb1 или debugfs my_dump соответственно. Если мы планируем осуществлять запись на диск, необходимо указать ключ -w: debugfs -w my_dump или debugfs -w /dev/sdb1.
Чтобы просмотреть список удаленных файлов, даем команду lsdel (или lsdel t_sec, где t_sec — количество секунд, истекших с момента удаления файла). На экране появится список удаленных файлов (разумеется, без имен). Файлы, удаленные более t_sec секунд назад (если эта опция задана), в данный список не попадут.
Команда cat < N > выводит содержимое текстового файла на терминал. Здесь < N > — номер inode, заключенный в угловые скобки. При выводе двоичных файлов разобрать смысл отображаемой на экране информации практически невозможно. Такие файлы должны сбрасываться в дамп командой dump < N > new_filе_name, где new_file_name — новое имя файла (с путем), под которым он будет записан в файловую систему, из-под которой был запущен отладчик debugfs. Файловая система восстанавливаемого раздела при этом остается неприкосновенной. Иными словами, команда должна даваться без ключа --w.
При желании можно восстановить файл непосредственно на самой восстанавливаемой файловой системе (что особенно удобно при восстановлении больших файлов). В этом нам поможет команда undel < N > undel_file_name, где undel_file_name — имя, которое будет присвоено файлу после восстановления.
Внимание!
Выполняя такую операцию, помните, что команда undel крайне агрессивна и деструктивна по своей природе. Она затирает первую свободную запись в таблице каталогов, делая восстановление оригинальных имен невозможным.
Команда stat < N > отображает содержимое inode в удобочитаемом виде, а команда mi < N > позволяет редактировать их по своему усмотрению. Для ручного восстановления файла (откровенно говоря, этого не пожелаешь и врагу) мы должны установить счетчик ссылок (link count) на единицу, а время удаления (deletion time), наоборот, сбросить в ноль. Затем отдать команду seti < N >, помечающую данный inode как используемый, и для каждого из блоков файла выполнить команду setb X, где X — номер блока.
Совет
Перечень блоков, занимаемых файлом, можно просмотреть с помощью команды stat. В отличие от lde, она отображает не только непосредственные, но и косвенные блоки, что несравненно удобнее.
Остается только дать файлу имя, что осуществляется путем создания ссылки на каталог (directory link). Сделать это можно с помощью команды ln < N > undel_file_name, где undel_file_name — имя, которое будет дано файлу после восстановления (при необходимости имя восстанавливаемого файла указывается с полным путем).
Внимание!
Создание ссылок на каталог необратимо затирает оригинальные имена удаленных файлов.
После присвоения имени восстановленному файлу полезно дать команду dirty, чтобы файловая система была автоматически проверена при следующей загрузке. Как вариант, можно выйти из отладчика и вручную запустить команду fsck с ключом -f, форсирующим проверку.
Теперь перейдем к восстановлению оригинального имени. Рассмотрим простейший случай, когда каталог, содержащий удаленный файл (также называемый родительским каталогом), все еще цел. В этом случае следует дать команду stat dir_name и запомнить номер inode, возвращенный этой командой.
Затем следует дать отладчику команду dump < INODE > dir_file, где INODE — номер сообщенного индексного дескриптора, a dir_file — имя файла "родной" файловой системы, в которую будет записан дамп. Полученный дамп следует загрузить в шестнадцатеричный редактор и просмотреть его содержимое в "сыром" виде. Все имена будут там. При желании можно написать утилиту-фильтр, выводящую только удаленные имена. На Perl это не замет и десяти минут.
А как быть, если родительский каталог тоже удален? В этом случае и он будет помечен как удаленный! Выводим список удаленных индексных дескрипторов, выбираем из этого списка каталоги, формируем перечень принадлежащих им блоков и сохраняем дамп в файл, который затем следует просмотреть вручную или с помощью утилиты-фильтра. Как уже отмечалось, порядок расположения файлов в inode очень часто совпадает с порядком расположения файлов в каталоге, поэтому восстановление оригинальных имен в четырех случаях из пяти проходит на ура.
При тяжких разрушениях, когда восстанавливаемый файл приходится собирать по кусочкам, помогает команда dump_unused, выводящая на терминал все неиспользуемые блоки. Имеет смысл перенаправить вывод в файл, запустить hexedit и покопаться в этой куче хлама — это, по крайней мере, проще, чем искать по всему диску. На дисках, заполненных более, чем на три четверти, этот трюк сокращает массу времени.
Таким образом, можно сделать вывод о том, что отладчик debugfs в значительной мере автоматизирует восстановление удаленных файлов, однако восстановить файл с разрушенным inode он не способен, и без lde в данном случае не обойтись.
Восстановление удаленных файлов с помощью утилиты R-Studio
Утилита R-Studio for NTFS, вопреки своему названию, поддерживает не только NTFS, но и файловые системы ext2fs/ext3fs (рис. 8.7). С точки зрения обычных пользователей, это — хорошее средство для автоматического восстановления удаленных файлов. Утилита предоставляет интуитивно-понятный интерфейс, проста в управлении и в благоприятных ситуациях позволяет восстанавливать удаленные файлы несколькими щелчками мыши. К недостаткам R-Studio for NTFS можно отнести:
□ отсутствие гарантий на восстановление файлов;
□ невозможность восстановления имен удаленных файлов;
□ отсутствие поддержки ручного восстановления;
□ невозможность восстановления файлов с разрушенным inode, несмотря на то, что под ext2fs этого можно добиться достаточно простым путем.
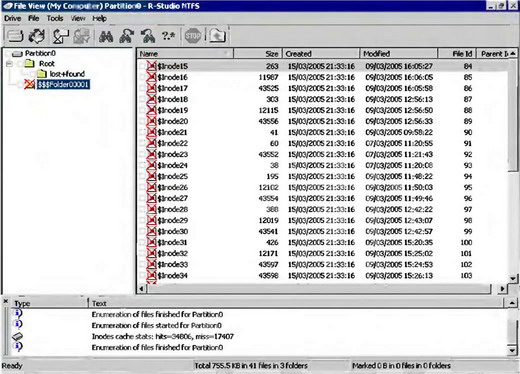
Рис. 8.7. Утилита R-Studio for NTFS восстанавливает удаленные файлы на разделе ext2fs. К сожалению, имена удаленных файлов не восстанавливаются
Обобщая, можно сказать, для профессионального использования R-Studio катастрофически не подходит.
Восстановление удаленных файлов на разделах ext3fs
Файловая система ext3fs фактически представляет собой аналог ext2fs, но с поддержкой протоколирования (в терминологии NTFS — транзакций). В отличие от ext2fs, она намного бережнее относится к массиву каталогов. Так, при удалении файла ссылка на inode уже не уничтожается, что упрощает автоматическое восстановление оригинальных имен. Тем не менее, поводов для радости у нас нет никаких, поскольку в ext3fs перед удалением файла список принадлежащих ему блоков тщательно вычищается. В результате этого восстановление становится практически невозможным (рис. 8.8). Нефрагментированные файлы с более или менее осмысленным содержимым (например, исходные тексты программ) еще можно собрать по частям, но и времени на это потребуется немало. К счастью, блоки косвенной адресации не очищаются, а это значит, что мы теряем лишь первые 12 * BLOCK_SIZE байт каждого файла. На типичном разделе объемом около 10 Гбайт значение BLOCK_SIZE обычно равно 4 или 8 килобайтам, т.е., реальные потери составляют менее 100 Кбайт. По современным понятиям, это сущие пустяки! Конечно, без этих 100 Кбайт большинство файлов просто не запустятся, однако найти на диске двенадцать недостающих блоков — вполне реальная задача. Если повезет, они окажутся расположенными в одном или двух непрерывных отрезках, но такое везение не гарантируется. Тем не менее, непрерывные отрезки из 6–12 блоков достаточно часто встречаются даже на сильно фрагментированных разделах.
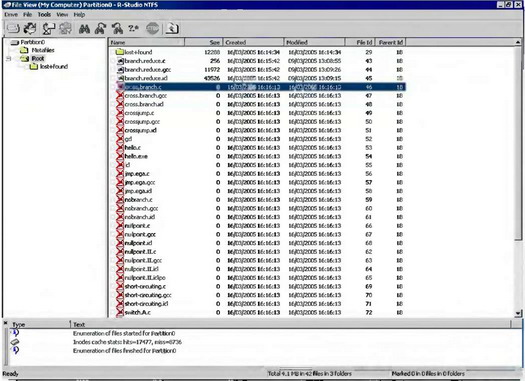
Рис. 8.8. Утилита R-Studio восстанавливает удаленные файлы на разделе ext3fs Имена файлов восстановлены, но нет самих файлов как таковых (их длина равна нулю, так как список блоков прямой адресации затерт)
Как мы будем действовать? Необходимо найти хотя бы один блок, гарантированно принадлежащий файлу и при этом расположенный за границей в 100 Кбайт от его начала. Это может быть текстовая строка, информация об авторских правах разработчика или любая другая характерная информация! Короче говоря, нам нужен номер блока. Пусть для определенности он будет равен 0x1234. Записываем его в обратном порядке так, чтобы младший байт располагался по меньшему адресу, и выполняем поиск 34h 12h 00h 00h — именно это число будет присутствовать в косвенном блоке. Отличить косвенный блок от всех остальных блоков (например, блоков, принадлежащих файлам данных) очень легко — он представляет собой массив 32-битных номеров блоков, более или менее монотонно возрастающих. Блоки с двойной и тройной косвенной адресацией отыскиваются по аналогичной схеме.
Проблема состоит в том, что одни и те же блоки в разное время могли принадлежать различным файлам, а это значит, что они могли принадлежать и различным косвенным блокам. Как разобраться, какой из найденных блоков является искомым? Да очень просто! Если хотя бы одна из ссылок косвенного блока указывает на уже занятый блок, данный косвенный блок принадлежит давно удаленному файлу и, следовательно, не представляет для нас интереса.
По правде говоря, debugfs обеспечивает лишь ограниченную поддержку ext3fs. В частности, команда lsdel всегда показывает ноль удаленных файлов, даже если удалить весь раздел. По этой причине вопрос выбора файловой системы отнюдь не так прост, каким его пытаются представить некоторые руководства по Linux для начинающих. Преимущества ext3fs на рабочих станциях и домашних компьютерах далеко не бесспорны и совсем не очевидны. Поддержка транзакций реально требуется лишь серверам, да и то не всем, а вот невозможность восстановления ошибочного удаленных файлов зачастую приносит большие убытки, чем устойчивость файловой системы к внезапным отказам питания.
Рекомендуемые источники
□ "Design and Implementation of the Second Extended File system" — подробное описание файловой системы ext2fs от разработчиков данного проекта (на английском языке). Это руководство доступно по адресу: http://e2fsprogs.sourceforge.net/ext2intro.html.
□ "Linux Ext2fs Undeletion mini-HOWTO" — краткая, но доходчивая инструкция по восстановлению удаленных файлов на разделах ext2fs (на английском языке). Данная инструкция доступа по адресу: http://www.praeclarus.demon.co.uk/tech/e2-undel/howto.txt.
□ "Ext2fs Undeletion of Directory Structures mini-HOWTO" — краткое руководство по восстановлению удаленных каталогов на разделах ext2fs (на английском языке): http://www.faqs.org/docs/Linux-mini/Ext2fs-Undeletion-Dir-Struct.html.
□ "HOWTO-undelete" — еще одно руководство по восстановлению удаленных файлов на разделах ext2fs с помощью редактора lde (на английском языке): http://lde.sourceforge.net/UNERASE.txt.
Восстановление удаленных файлов на разделах UFS
Файловая система UNIX (UNIX File System, UFS) — это основная файловая система для систем BSD, устанавливаемая по умолчанию. Многие коммерческие варианты UNIX также используют либо UFS в чистом виде, либо одну из файловых систем, созданных на ее основе и очень на нее похожих. В отличие от ext2fs, хорошо документированной и изученной вдоль и поперек, UFS в доступной литературе описана крайне поверхностно. Единственным источником информации становятся исходные тексты, в которых не так-то просто разобраться! Существует множество утилит, восстанавливающих уничтоженные данные (или, во всяком случае, пытающихся это делать), но на практике все они оказываются неработоспособными. Это, в общем-то, и неудивительно, поскольку автоматическое восстановление удаленных файлов под UFS невозможно в принципе. Тем не менее, файлы, удаленные с разделов UFS, вполне возможно восстановить вручную, если, конечно, знать как это делается.
Исторический обзор
UFS ведет свою историю от файловой системы s5. Это — самая первая файловая система, написанная для UNIX в далеком 1974 году. Файловая система s5 была крайне простой и неповоротливой (по некоторым данным, ее производительность составляла от 2 до 5 процентов от "сырой" производительности "голого" диска). Тем не менее, понятия суперблока (super-block), файловых записей (inodes) и блоков данных (blocks) в ней уже существовали.
В процессе работы над дистрибутивом 4.2 BSD, вышедшим в 1983 году, оригинальная файловая система была несколько усовершенствована. Были добавлены длинные имена файлов и каталогов, символические ссылки и т.д. Так родилась UFS.
В 4.3 BSD, увидевшей свет уже в следующем году, улучшения носили намного более радикальный, можно даже сказать — революционный — характер. Появились концепции фрагментов (fragments) и групп цилиндров (cylinder groups). Быстродействие файловой системы существенно возросло, что и позволило разработчикам назвать ее быстрой файловой системой (Fast File System, FFS).
Все последующие версии линейки 4. x BSD прошли под знаменем FFS, но в 5. x BSD файловая система вновь изменилась. Для поддержки дисков большого объема ширину всех адресных полей пришлось удвоить: 32-битная нумерация фрагментов уступила место 64-битной. Были внесены и другие, менее существенные усовершенствования.
Таким образом, на практике мы имеем дело с тремя различными файловыми системами, не совместимыми друг с другом на уровне базовых структур данных. Тем не менее, некоторые источники склонны рассматривать FFS как надстройку над UFS. Например, документ "Little UFS2 FAQ" (http://sixshooter.v6.thrupoint.net/jeroen/faq.html) утверждает, что UFS и UFS2 определяют раскладку данных на диске, причем FFS реализована как надстройка над UFS/UFS2 и отвечает за структуру каталогов и оптимизацию операций доступа к диску. Однако если заглянуть в исходные тексты файловой системы, можно обнаружить два подкаталога — /ufs и /ffs. В /ffs находится определение суперблока (базовой структуры, отвечающей за раскладку данных), а в /ufs — определения inode и структуры каталогов, что опровергает данный тезис, с точки зрения которого все должно быть с точностью "до наоборот".
Чтобы не увязнуть в болоте терминологических тонкостей, под UFS мы будем понимать основную файловую систему 4.5 BSD, а под UFS2 — основную файловую систему 5.x BSD.
Структура UFS
В целом, UFS очень похожа на ext2fs — те же inode, блоки данных, файлы, каталоги. Тем не менее, есть между этими файловыми системами и различия. В ext2fs имеется только одна группа индексных дескрипторов (inodes), и только одна группа блоков данных для всего раздела. В отличие от ext2fs, UFS делит раздел на несколько зон одинакового размера, называемых группами цилиндров. Каждая зона имеет свою группу индексных дескрипторов и свою группу блоков данных, независимых ото всех остальных зон. Иначе говоря, индексные дескрипторы описывают блоки данных той и только той зоны, к которой они принадлежат. Это повышает быстродействие файловой системы, так как головка жесткого диска совершает более короткие перемещения. Кроме того, такая организация упрощает процедуру восстановления при значительном разрушении данных, поскольку, как показывает практика, обычно гибнет только первая группа индексных дескрипторов. Случаи, когда гибнут все группы, встречаются крайне редко. Предполагаю, что для того, чтобы умышленно этого добиться, диск потребуется положить под гидравлический пресс.
Диаграмма, осуществляющая сравнение файловых систем s5 и UFS, представлена на рис. 8.9. В UFS каждый блок разбит на несколько фрагментов фиксированного размера, предотвращающих потерю свободного пространства в хвостах файлов. В результате этого использование блоков большого размера уже не кажется расточительной идеей, напротив, это увеличивает производительность и уменьшает фрагментацию. Если файл использует более одного фрагмента в двух несмежных блоках, он автоматически перемещается на новое место, в наименее фрагментированный регион свободного пространства. Таким образом, фрагментация в UFS очень мала или же совсем отсутствует, что существенно облегчает восстановление удаленных файлов и разрушенных данных.
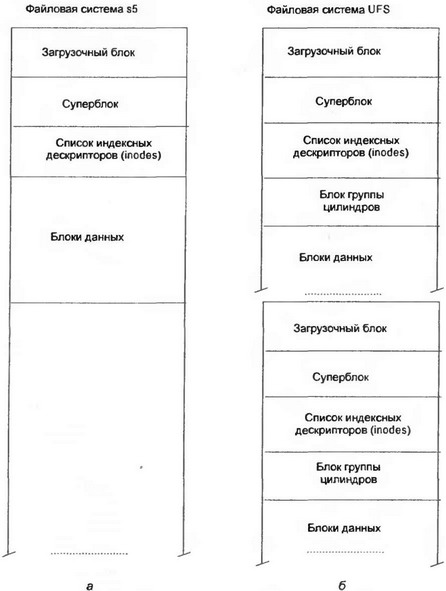
Рис. 8.9. Структура файловых систем s5/ext2fs (а) и UFS (б)
Адресация ведется либо по физическим смещениям, измеряемым в байтах и отсчитываемым от начала группы цилиндров (реже — от начала раздела UFS), либо в номерах фрагментов, отсчитываемых от тех же самых точек. Допустим, размер блока составляет 16 Кбайт, разбитых на 8 фрагментов. Тогда 69-й сектор будет иметь смещение 512 * 69 == 35328 байт или 1024 * (16/8)/512 * 69 == 276 фрагментов.
В начале раздела расположен загрузочный сектор, затем следует суперблок, за которым находится одна или несколько групп цилиндров (рис. 8.10). Для перестраховки копия суперблока дублируется в каждой группе. Загрузочный сектор не дублируется, но по соображениям унификации и единообразия под него просто выделяется место, таким образом, относительная адресация блоков в каждой группе остается неизменной.
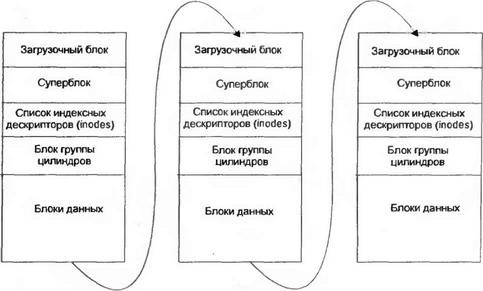
Рис. 8.10. Последовательно расположенные группы цилиндров
В UFS суперблок располагается по смещению 8192 байт от начала раздела, что соответствует 16-му сектору. В UFS2 он "переехал" на 65536 байт (128 секторов) от начала, освобождая место для дисковой метки и первичного загрузчика операционной системы, а для действительно больших (в исходных текстах они обозначены как "piggy") систем предусмотрена возможность перемещения суперблока по адресу 262144 байт (целых 512 секторов).
Среди прочей информации суперблок содержит:
□ cblkno — смещение первой группы блока цилиндров, измеряемое во фрагментах, отсчитываемых от начала раздела;
□ fs_iblkno — смещение первого inode в первой группе цилиндров (фрагменты от начала раздела);
□ fs_dblkno — смещение первого блока данных в первой группе цилиндров (фрагменты от начала раздела);
□ fs_ncg — количество групп цилиндров;
□ fs_bsize — размер одного блока в байтах;
□ fs_fsize — размер одного фрагмента в байтах;
□ fs_frag — количество фрагментов в блоке;
□ fs_fpg — размер каждой группы цилиндров, выраженный в блоках (также может быть найден через fs_cgsize).
Для перевода смещений, выраженных во фрагментах, в номера секторов, служит следующая формула: sec_n(fragment_offset) == fragment_offset* (fs_bsize/fs_frag/512) или ее более короткая разновидность: sec_n(fragment_offset) == fragment_offset*fs_fsize /512.
Структура суперблока определена в файле /src/ufs/ffs/fs.h и в упрощенном виде выглядит, как показано в листинге 8.7.
Поиск по сайту: