АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Кластеризация с помощью с помощью алгоритма k-means
Рассмотрим механизм кластеризации, реализованный на алгоритме k-means, основываясь на данных роста численности населения по регионам РФ. Исходная таблица находится в файле «Регионы.txt». Задача состоит в распределении регионов на функциональные группы по демографической картине в них и выявлении скрытых закономерностей.
Вначале необходимо осуществить импорт рассматриваемых данных из файла. После этого запустить Мастер обработки «Кластеризация». При запуске Мастера необходимо настроить назначения столбцов, т.е. выбрать свойства, по которым будет происходить группировка объектов. Укажите столбцам «Численность населения» и «Регион» назначение «информационное», а остальным полям – «входное».
На следующем шаге Мастера необходимо настроить способ разделения исходного множества данных на тестовое и обучающее, а также количество примеров в том и другом множестве. Укажите, что данные обоих множеств берутся случайным образом, и определите все множество как обучающее.
Следующий шаг предлагает настроить параметры кластеризации, определить на какое количество кластеров будет распределяться исходное множество. По мнению экспертов в стране наблюдается четыре тенденции развития регионов, поэтому выберем фиксированное количество кластеров равное четырем.
Для отображения полученных групп кластеров выбрать из списка визуализаторов способы отображения данных: «Профили кластеров», «Куб» «Матрица сравнений», «Связи кластеров».
Для настройки визуализатора «Куб» необходимо выбрать рассматриваемые показатели как факты, а номер кластера и регионы как измерение.
На 9 шаге задать отображение фактов как среднее по рассматриваемое группе.
Общую структуру сформированных алгоритмом кластеров можно просмотреть в визуализаторе «Профили кластеров» (рис. 8.1). В нем представлены все рассматриваемые свойства вместе с характером влияния их на состав кластера. Основным фактором, определяющим состав кластера, является значимость свойств, выраженная в процентах.
Алгоритм автоматически разбил регионы на четыре кластера с разной поддержкой и разными процентами значимости свойств.
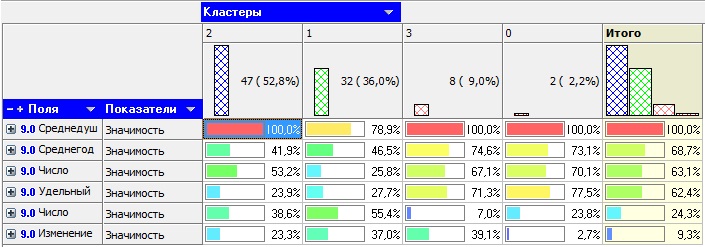
Рис. 8.1
Третий кластер является показателем демографической обстановки страны, так как собрал в себя максимальное количество регионов – 47 из 89.
Малозначимым и почти не влияющим свойством на распределение является изменение численности населения по сравнению с предыдущим годом, при необходимости данным свойством можно пренебречь.
С помощью кнопки переименование кластеров можно им присвоить им рабочие названия (рис. 8.2).

Рис. 8.2
Наиболее ярко выраженными кластерами по заданным свойствам являются нулевой и первый кластер: они максимально отличаются от остальных рассматриваемых групп значениями свойств, и минимальной поддержкой. Подтвердим предположение, используя визуализатор «Матрица сравнений». Наименьшая степень сходства между первым и нулевым кластером 12,76% (рис. 8.3).

Рис. 8.3
Так же оценить похожесть кластеров можно с помощью визуализатора «Связи кластеров». Наиболее похожим на нулевой кластер является второй, он имеет наибольшую степень связи, отображаемую на диаграмме красным цветом (рис. 9.4). При необходимости данные кластеры как наиболее похожие можно объединить.
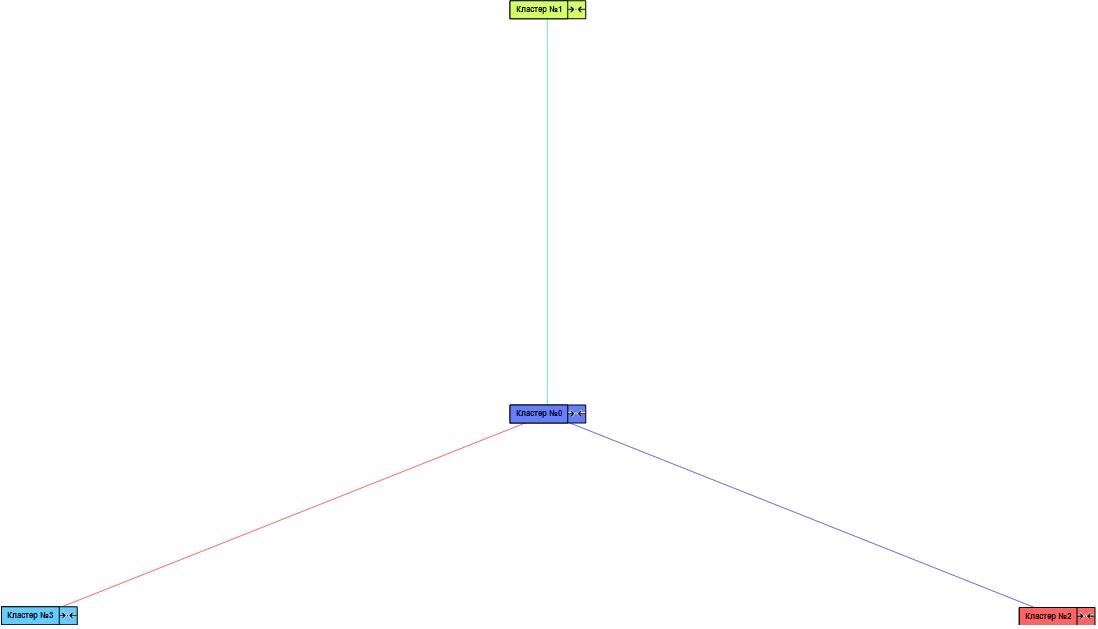
Рис. 8.4
Результаты по сформированным кластерам наиболее удобно рассматриваются с помощью визуализатора «Куб», в который встроена кросс-диаграмма, изображающая полученные кластеры в графическом виде, что существенно упрощает анализ (рис. 8.5).
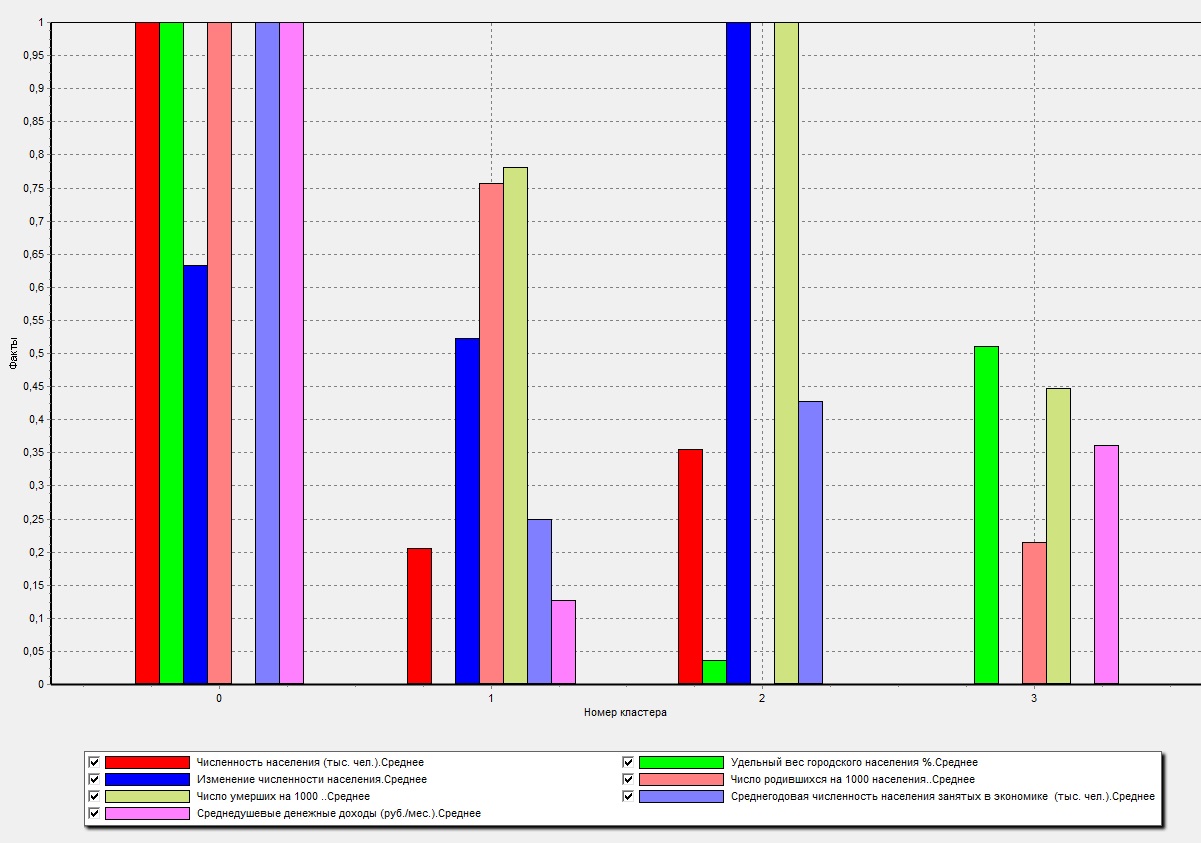
Рис. 8.5
Определить какой регион максимально похож на выбранный можно с помощью «Диаграммы связи». Определим семь похожих на Санкт-Петербург регионов по демографической обстановке. Зададим количество связей равным - 7, а Санкт-Петербург поместим в центр. Челябинская область максимально схожа с Санкт-Петербургом, степень сходства – 91,6%. В правой стороне окна можно проанализировать демографические коэффициенты для этих двух регионов (рис. 8.6).

Рис. 8.6
Поиск по сайту: