АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Оцінка тісноти, суттєвості й лінійності (нелінійності) зв'язку між змінними
Тіснота зв'язку між змінними характеризується ступенем відхилення (розсіяння) досліджуваних точок біля теоретичної лінії регресії. Чим ближче окремі спостереження розташовані до теоретичної лінії регресії, тим більше повна залежність у по х.
Кутовий коефіцієнт лінійного кореляційного зв'язку між у і х, який показує, на скільки одиниць в середньому зміниться функція, якщо аргумент збільшується (зменшується) на одиницю свого вимірювання не може служити показником тісноти зв'язку між змінними. У цьому випадку його чисельне значення залежить від прийнятих одиниць вимірювання змінних.
Для оцінки тісноти зв'язку між змінними використовується емпіричне кореляційне відношення (η2y/х), яке є часткою дисперсії (коливаємості) функції у за рахунок впливу даного аргументу х. У даному випадку загальна (повна) дисперсія розкладається на дві частини – дисперсію усередині кожного інтервалу зміни функції σ 2y/х, яка не залежить від впливу Х, і дисперсію середніх значень функції δ  , яка викликана впливом аргументу, тобто
, яка викликана впливом аргументу, тобто
σ2y= σ2y/х+ δ . (3.14)
Звідси формула для оцінки тісноти зв'язку між змінними має вигляд
 , (3.15)
, (3.15)
а в разі згрупованих даних
 , (3.16)
, (3.16)
де 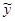 I - розрахункове значення функції;
I - розрахункове значення функції;
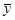 - середнє значення функції за вибіркою;
- середнє значення функції за вибіркою;
n - обсяг вибірки;
к - кількість інтервалів зміни функції;
mi – число спостережень у в кожному інтервалі зміни.
Кореляційне відношення не залежить від одиниць вимірювання змінних, що вивчаються. Воно показує, яку частину загальної дисперсії σ2y можна віднести за рахунок зміни аргументу на одну σ2х.
При цьому характеристика η2y/х тим точніше визначає частку впливу Х на загальну дисперсію у, чим менше варіюється залишкова дисперсія σ2y/х при кожному Х. Якщо ηy/х=1, то має місце функціональна залежність у від х. Якщо ηy/х=0 – у кореляційно не залежить від х.
У разі лінійної залежності змінних дисперсію середніх значень функції можна записати у вигляді
 (3.17)
(3.17)
Спростивши це відношення:
δy2= К2 σ2х. (3.18)
Тоді показник тісноти зв'язку для випадку лінійної залежності буде
 (3.19)
(3.19)
Отримане відношення служить для визначення вимірника тісноти зв'язку між змінними в разі їх лінійної залежності, і має назву коефіцієнта кореляції ry/х.
Якщо замість К підставити формулу для його обчислень  , то матимемо
, то матимемо
 . (3.20)
. (3.20)
Коефіцієнт кореляції показує, на яку частину середнього квадратичного відхилення або σy змінюється функція у, якщо аргумент Х збільшується (зменшується) на своє середньоквадратичне відхилення σх. Знак коефіцієнта кореляції співпадає із знаком коефіцієнта регресії, а його чисельне значення коливається в межах
-1≤ry/х≤1. (3.21)
Суттєвість коефіцієнта кореляції при заданому рівні значущості  =0,05 або 5% перевіряємо за умовою
=0,05 або 5% перевіряємо за умовою
 , (3.22)
, (3.22)
де t визначається за умовою 2ф(t).
Приклад. Визначити гарантійну вірогідність істотності коефіцієнта кореляції ry/х =-0,745 при n=52 спостережень.
Вирішення
 . (3.23)
. (3.23)
При =0,05 табличне значення t=1,96, що значно менше розрахункового. При t=12,07 довірчий інтервал в генеральній сукупності містить коефіцієнт кореляції з довірчою вірогідністю
P=2ф(12,07)=100%. (3.24)
Лінійність (нелінійність) зв'язку між змінними перевіряється шляхом:
- порівняння абсолютних значень (ry/х)= ηy/х;
- статистично з використанням довірчого інтервалу. При цьому кореляційне емпіричне відношення ηy/х повинне покриватися довірчим інтервалів для (ry/х):
 (3.25)
(3.25)
з довірчою вірогідністю 2ф(tα)=1-α.
Отже, якщо нерівність задовольняється при =0,05, то приймаємо гіпотезу лінійності, якщо ж нерівність не задовольняється, то приймаємо гіпотезу нелінійної кореляційної залежності між у і х.
Приклад. Виявити лінійність (нелінійність) кореляційної залежності у разі, коли ηy/х =0,525
ry/х =0,439 і n=154 при =0,05.
Вирішення.
Визначаємо межі довірчого інтервалу:

0,365≤ ηy/х≤0,513.
Значення ηy/х =0,525 не потрапляє в довірчий інтервал, що свідчить про нелінійність зв'язку.
Завершальним дослідженням парного рівняння є перевірка відповідності виведеного рівняння описуваному реальному процесу. Якщо отримано декілька рівнянь регресії, то кращим слід читати те з них, яке ближче до закономірності по суті досліджуваного процесу, що вивчається. Слід оцінити ступінь близькості результатів розрахунків по кожному з отриманих рівнянь до звітних даних. Цей ступінь оцінюється по залишковій теоретичній дисперсії  , яка характеризує розкид досліджених точок кореляційного поля навколо теоретичної лінії регресії під впливом чинників, що не враховані в отриманому рівнянні.
, яка характеризує розкид досліджених точок кореляційного поля навколо теоретичної лінії регресії під впливом чинників, що не враховані в отриманому рівнянні.
Залишкова теоретична дисперсія визначається з рівняння
 , (3.26)
, (3.26)
де n - обсяг вибірки;
Р - число параметрів рівняння;
К - число інтервалів;
h - число спостережень в i-му інтервалі;
yij - значення досліджених даних функціональної ознаки;
- розрахункове значення функціональної ознаки, обчислене за рівнянням регресії.
Якщо складено декілька рівнянь регресії і для кожного обчислена залишкова дисперсія, то з декількох рівнянь регресії, рівноцінних по суті, перевагу слід віддати тому, в якого залишкова дисперсія менше.
Для управління регресії з одним аргументом Х залишкову дисперсію обчислюємо за формулою
 . (3.27)
. (3.27)
Одним з ознак згоди початкових даних з отриманим рівнянням служить нормальність розподілу відхилень досліджених даних від розрахункових (yij- xi) зі середнім значенням, рівним нулю, і середнім квадратичним відхиленням, рівним σy/х. Чим ближче розподіл цих відхилень до вказаного нормального закону, тим краще узгоджуються вихідні дані з виведеним рівнянням регресії. Обчисливши всі відхилення (yij- xi), перевіряємо наявність нормального закону їх розподілу візуально і за критерієм згоди.
Таким чином, дослідження управління в тій або іншій формі полягає у визначенні його параметрів (із вирішення системи нормальних рівнянь), підстановці в отримане рівняння всіх вихідних значень аргументу, розрахунку відповідних значень ij, порівнянні розрахункових значень i із вихідними значеннями, обчисленні суми квадратів відхилень розрахункових значень від вихідних і визначення залишкової дисперсії  2y/х. Найкраща форма визначається за найменшою залишковою дисперсією. За такою схемою визначаються форми зв'язку у по всіх аргументах.
2y/х. Найкраща форма визначається за найменшою залишковою дисперсією. За такою схемою визначаються форми зв'язку у по всіх аргументах.
Існує і критерій адекватності, запропонований Фішером, заснований на порівнянні залишкової теоретичної дисперсії 2y/х і загальної дисперсії σy2. Розглядається відношення  і порівнюється з табличним (для
і порівнюється з табличним (для  % Фішера знайдено розподіл і складена спеціальна таблиця) при заданому рівні значущості і різних ступенях свободи.
% Фішера знайдено розподіл і складена спеціальна таблиця) при заданому рівні значущості і різних ступенях свободи.
Загальна дисперсія σy2 досліджених даних від їх середнього значення встановлюється з урахуванням числа ступенів свободи  :
:
 , (3.28)
, (3.28)
де К – число інтервалів у вибіркових даних.
Залишкова теоретична дисперсія 2y/х встановлюється як різниця розрахункових i і середніх інтервальних значень  i з урахуванням числа ступенів свободи d1=K-P і d2=n-K,
i з урахуванням числа ступенів свободи d1=K-P і d2=n-K,
де Р – число параметрів управління.
Якщо рас ≤ табл, то при заданому рівні значущості складене рівняння регресії затверджується. Вірогідність помилки тим менше чим більше рівень значущості α%.
У разі, коли чисельник 2y/х менше знаменника σy2, то міняємо їх місцями разом з відповідними ступенями свободи d1=K-P і d2=n-K.
Приклад. Загальна дисперсія σy2=41,5 при n=154 і К=12.
Залишкова дисперсія 2y/х=34,44 при К=12 і Р=3 (Р=3 в квадратному рівнянні регресії).
Вирішення.
 , оскільки σy2> 2y/х, переходимо до відношення із ступенями свободи D1=154-12=142, d2=12-3=9 розр.=
, оскільки σy2> 2y/х, переходимо до відношення із ступенями свободи D1=154-12=142, d2=12-3=9 розр.=  =1,21,
=1,21,
за таблицею 5%(142,9)=2,75 20%(142,9)=1,7.
Отже, знайдене квадратне рівняння регресії з високою надійністю узгоджується з вихідними даними.
Приклад. З метою кореляційного аналізу собівартості перевезення 10 пасажирів по одному з депо зібрано щомісячні дані за останні три роки. Обсяг вибірки складає n=36 спостережень (табл. 3.1).
Таблиця 3.1 – Показники діяльності депо
| № n/n | Собівартість перевезення 10 пасажирів, (у) коп. | Середньодобове перебування на лінії рухомого складу, (х) год. | № n/n | Собівартість перевезення 10 пасажирів, (у) коп. | Середньодобове перебування рухомого складу на лінії, (х) год. | ||||||
| 80,94 | 11,61 | 79,98 | 11,85 | ||||||||
| 82,79 | 11,52 | 77,72 | 11,78 | ||||||||
| 72,23 | 12,18 max | 80,11 | 11,63 | ||||||||
| 72,11 min | 12,18 | 81,50 | 11?59 | ||||||||
| 78,92 | 11,72 | 81,94 | 11,67 | ||||||||
| 74,76 | 11,98 | 81,98 | 11,61 | ||||||||
| 77,91 | 11,67 | 85,98 max | 11,55 | ||||||||
| 77,84 | 11,68 | 78,36 | 11,72 | ||||||||
| 76,14 | 11,83 | 79,51 | 11,78 | ||||||||
| 74,66 | 12,03 | 74,24 | 11,91 | ||||||||
| 79,02 | 11,76 | 73,10 | 11,95 | ||||||||
| 83,34 | 11,56 | 75,92 | 11,87 | ||||||||
| 79,20 | 11,78 | 81,31 | 11,66 | ||||||||
| 78,96 | 11,80 | 83,05 | 11,55 | ||||||||
| 76,79 | 11,94 | 84,90 | 11,51 min | ||||||||
| 79,68 | 11,82 | 83,14 | 11,58 | ||||||||
| 74,08 | 11,88 | 81,99 | 11,67 | ||||||||
| 77,72 | 11,77 | 85,69 | 11,58 | ||||||||

| 2847,5 | 423,15 | |||||||||
1. Оскільки вихідні дані зібрані по одному об'єкту, їх статистична однорідність не перевіряємо.
2.Визначаємо статистичні характеристики ряду розподілу.
Варіаційний розмах у коливається наступним чином: Ray =ymax-ymin=85,98-72,11=13,87; відносний розмах  , розмах варіювання (розмір інтервалу) розраховуємо за формулою Стерджеса:
, розмах варіювання (розмір інтервалу) розраховуємо за формулою Стерджеса:
 . (3.29)
. (3.29)
Визначаємо початок першого інтервалу:
 . (3.30)
. (3.30)
Аналогічні розрахунки виконані для аргументу:
Rax=Xmax-Xmin=12,18-11,51=0,67, (3.31)
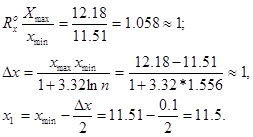 (3.32)
(3.32)
3. Складакємо ряди розподілу у і Х (таб.3.2).
Таблиця 3.2 - Ряди розподілу у і Х
| Інтервали | Середина інтервалу | Частота | Інтервали | Середина інтервалу | Частота |
| ∆y | yi ср. | mi | ∆X | Xi ср. | mi |
| 71-73 | 11,5-11,6 | 11,55 | |||
| 73-75 | 11,6-11,7 | 11,65 | |||
| 75-77 | 11,7-11,8 | 11,75 | |||
| 77-79 | 11,8-11,9 | 11,85 | |||
| 79-81 | 11,9-12,0 | 11,95 | |||
| 81-83 | 12,0-12,1 | 12,05 | |||
| 83-85 | 12,1-12,2 | 12,15 | |||
| 85-87 | 12,2-12,3 | 12,25 | - |
4. Розраховуємо основні числові характеристики: середня арифметична для показника у:
 . (3.33)
. (3.33)
Середньоквадратичне відхилення і дисперсія:
 ; (3.34)
; (3.34)
 . (3.35)
. (3.35)
Коефіцієнт варіації:
 . (3.36)
. (3.36)
Аналогічно для Х
 , (3.37)
, (3.37)
5. Досліджуємо закон розподілу.
5.1.Складаємо таблицю розподілу дослідних даних у, обчислюємо середнє значення і дисперсію σ2y.
5.2.Будуємо гістограму і розробляємо припущення про закон розподілу у.
5.3.Накладаємо відповідну диференціальну криву розподілу і візуально визначаємо ступінь близькості гістограми до гіпотетичної теоретичної кривої.
5.4.Перевіряємо наявність передбачуваного закону розподілу за допомогою деякого статистичного критерію згоди.
Таблиця 3.3 - Розподіл досліджених значень у
| Інтервали | Середнє значення інтервалу | частота | Відносна частота | Умовні варіації | Розрахунок середнього значення | Розрахунок дисперсії | Значення у в стандартизованномумасштабі | Значення диференційованої функції | Емпіричні частоти | Ординати теоретичного розподілу | Розрахункові частоти | |
| yk-1-yk | ycp. | mi | mi/n | y1cp/ | mi y1cp. | Mi y12cp. | (y1cp/- )2 mi
| Формула | формула | формула | формула | формула |
| 71-73 | 0,055 | -4 | -8 | 41,496 | 2,502 | 0,0175 | 0,027 | 0,0064 | 0,461 | |||
| 73-75 | 0,111 | -3 | -12 | 50,552 | 1,776 | 0,084 | 0,056 | 0,031 | 2,232 | |||
| 75-77 | 0,167 | -2 | -12 | 39,168 | 1,049 | 0,231 | 0,083 | 0,084 | 6,048 | |||
| 77-79 | 0,194 | -1 | -7 | 16,926 | 0,323 | 0,379 | 0,097 | 0,1376 | 9,907 | |||
| 79-81 | 0,194 | 2,156 | 0,403 | 0,363 | 0,09 | 0,131 | 9,489 |
Продовження табл. 3.3
| 81-83 | 
| 0,594 | 1,129 | 0,212 | 0,042 | 0,077 | 25,544 | |||||
| 83-85 | 0,139 | 10,440 | 1,856 | 0,072 | 0,069 | 0,0262 | 11,886 | |||||
| 85-87 | 0,055 | 11,956 | 2,583 | 0,014 | 0,027 | 0,0051 | 00,367 | |||||
| -20 | 1173.83 | J35.924 |
Для побудови гістограми обчислюємо висоти прямокутників
 . (3.38)
. (3.38)
 Розрахунки наведені в табл.3.3. Гістограма і полігон нагадують нормальний розподіл (рис.3.1).
Розрахунки наведені в табл.3.3. Гістограма і полігон нагадують нормальний розподіл (рис.3.1).
Рис.3.1 - Гістограма і полігон
 (3.39)
(3.39)
Порівнюється відношення Х2 табл при п'яти ступенях свободи з розрахунковим Х2розр.:
 . (3.40)
. (3.40)
Таким чином, Х2стат. 5%>Х2расч.,.тобто статистичне значення Х2 потрапляє в допустиму область при 95% рівні значущості. Гіпотеза наявності нормального закону розподілу собівартості пасажироперевезень затверджується.
6. Відкидаємо окремі значення, різко відмінні від основної маси спостережень. Якщо значення у розподілене нормально, найбільші випадкові відхилення від середнього за абсолютною величиною не перевищують 3  з достовірною вірогідністю 99,7%.
з достовірною вірогідністю 99,7%.
У даній статистичній сукупності =78,89 і σy =2,753. Отже, в масив для подальшої обробки слід включати всі значення у, що не виходять за межі 78,89-3.2,753=70,631 і 78,89+3.2,753=87,149.
У прикладі, що розглядаємо, уmin=72,11 і уmax=85,98, отже, всі значення включаються для подальшої обробки.
7.Перевіряємо достатність кількості спостережень за умови, що відхилення середнього вибіркового виб. від середнього генерального ген. не перевершує певну величину ε з гарантійною вірогідністю Р=95%.
У даному прикладі σy2=7,580, тоді маємо 2Ф(t)=0,95 t=1,96;
 . (3.41)
. (3.41)
Отже, вибірка в 36 спостережень задовольняє поставленій вимозі.
8. Складаємо рівняння регресії у собівартості пасажироперевезень по Х (середньодобовому перебуванню рухомого складу на лінії).
8.1. За дослідженими даними будуємо кореляційне поле в декартовій системі координат (рис.3.2). Для наближеного співвідношення сторін графіка у по Х використовуємо відносний варіаційний розмах
 . (3.42)
. (3.42)

Рис. 3.2 - Кореляційне поле, емпірична і теоретична лінії регресії
8.2. Складаємо кореляційну таблицю (табл. 3.4.), обчислюємо інтервальні середні I і будуємо емпіричну лінію регресії по Х.
8.3. Складаємо рівняння собівартості пасажироперевезень за середньодобовим перебуванням рухомого складу на лінії. Розрахунки всіх потрібних сум в умовних варіантах наведені в табл. 3.4, =кх+b:
 (3.43)
(3.43)
σх2= σх1 2. (3.44)
∆Х2=2,559*0,12=0,0256; (3.45)
σх=0,160; (3.46)
b= +к  ; b=79,12-(-19,843)*11,753=312,24. (3.47)
; b=79,12-(-19,843)*11,753=312,24. (3.47)
Отже, рівняння регресії має вигляд:
=312,24-19,843 Х. (3.48)
8.4. Визначаємо емпіричне кореляційне відношення ηу/х, коефіцієнт кореляції ry/x і його середнє квадратичне відхилення σ2.
Коефіцієнт кореляції рівний
 (3.49)
(3.49)
Коефіцієнт кореляції достатньо великий і суттєвий при високій гарантійній ймовірності:
 (3.50)
(3.50)
Кореляційне відношення
 (3.51)
(3.51)
Лінійність кореляційної залежності гарантується при високому рівні значущості. Дійсно, кореляційне співвідношення ηу/х знаходиться в довірчому інтервалі для ry/x:

 (3.52)
(3.52)
при 5% рівні значущості t=1,96.
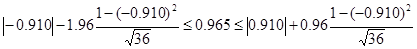 . (3.53)
. (3.53)
0,854 ≤ 0,965 ≤ 0,967 (3.54)
Теоретична лінія регресії представлена на рис.3.2.
Парні рівняння регресії xj=d(xj) описують залежність функціональної ознаки від кожного окремо взятого чинника - аргументу без урахування його взаємозв'язку з іншими. Це може спотворювати дійсне положення, призводити до невиправданих висновків і пропозицій. Треба виявити відособлений "приватний вплив" кожного окремого чинника, які в досліджуваному процесі виступають у взаємозв'язку.
Проблема відшукання такого рівняння, яке показало б ізольований вплив на показник кожного окремого чинника, що вивчається, розв'язується за допомогою рівняння множинної регресії.
Ставиться завдання визначення такої функції F(X1,X2...Xp), яка математично описувала б зміну середнього значення ознаки у, що вивчається, залежно від аргументу Х1, Х2..Хр з урахуванням особливостей процесу і близьким охопленням вихідних даних:
х1, х2,....хр=F(Х1, Х2...Хр). (3.55)
Поставлене завдання розв'язується на основі знання сутності процесу і попереднього виявлення одновимірної залежності
хj=dj (Xj), де j=1,2...P. (3.56)
При об'єднанні парних рівнянь в єдине множинне необхідно чітко розрізняти дві ситуації:
- при виборі рівнянь парної регресії хj= d (Xj) (1) змінна у не піддавалася функціональним перетворенням;
- при виборі рівнянь парної регресії хj1= d (Xj) (2) величина у піддавалася функціональним перетворенням виду  , ℓg y, y2 та ін.
, ℓg y, y2 та ін.
У першій ситуації будь-яка парна залежність може бути з'єднана в множинне рівняння, яке можна отримати підсумовуванням виразів типу (1):
х1, х2..хр=F(X1, X2...Xp)=  1(x1) + 2(x2)+ .+ p(xp) (3),
1(x1) + 2(x2)+ .+ p(xp) (3),
де j=d(xj) – функція типу ij (xj) з невизначеними коефіцієнтами, обчисленими за способом найменших квадратів. Так, рівняння прямої =А1Х1+В1 і гіперболи  об'єднуються в рівняння множинної регресії
об'єднуються в рівняння множинної регресії  в якому параметри а, b і с визначаються методом найменших квадратів з системи нормальних рівнянь:
в якому параметри а, b і с визначаються методом найменших квадратів з системи нормальних рівнянь:
 (3.57)
(3.57)
У другій ситуації парні рівняння (1) об'єднуються в єдине множинне при будь-якому виді функції (2), але тільки у тому випадку, коли всі функціональні перетворення у однакові. У такій ситуації функціональні середні всіх парних рівнянь (2) співпадають і за допомогою загального множника перетворюють в шукану середню (звичайно в арифметичну середньою).
Як було рекомендовано вище, підбираємо функціональні перетворення змінних, рівняння виду (2) до лінійного виду, а значить шукане допоміжне множинне рівняння (3): перетвориться до вигляду
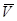 u1,u2….up=a1 u1+ a2 u2+….ap up. (3.58)
u1,u2….up=a1 u1+ a2 u2+….ap up. (3.58)
Отже, оперуючи далі перетвореними змінними V і Uj, можна обмежитися методикою складання лінійного множинного рівняння, використовуючи всі переваги лінійної регресії:
- попереднє знаходження стандартизованого рівняння V по U1, U2... Up за допомогою кореляційної матриці;
- дослідження зворотної кореляційної матриці;
- дослідження суттєвості й незалежності коефіцієнтів регресії;
- аналіз бета – коефіцієнтів;
- аналіз зміни детермінації як показника тісноти зв'язку.
Якщо об'єднується парна лінійна залежність виду =kx+b, то приходимо до вирішення задачі визначення множинної регресії вигляду
х1, х2… хр =а1 х1 + а2 х2 +…+ар хр (3.59)
або інакше як і в разі, коли у функціонально не перетворювався, коефіцієнти а1, а2…ар рівняння множинної регресії можуть бути визначені методом найменших квадратів:
х1, х2… хр- у=а1 (х1- 1) а2 (х2- 2)+……ар(хр- р). (3.60)
Проте при цьому буде утруднене зіставлення ступеня впливу окремих чинників-аргументів на функцію.
Більш зручно переходити до стандартизованого масштабу змінних, використовуючи формули
 , (3.61)
, (3.61)
При цьому слід мати на увазі, що всі середні значення стандартизованих величин tyx1, x2…xp т.е. і txi або xi рівні нулю, а їх дисперсії σij2 и σtxi2 =1.
Разом з тим коефіцієнти кореляції між стандартизованими величинами зберігають колишні значення, тобто rty = ryti, rtxi = rxi. У результаті стандартизації рівняння множинної регресії набуває вигляду
t xi = β1 t1 + β2 t2 +… + βp tp, (3.62)
де, β1, β2…. β р – невідомі коефіцієнти регресії в стандартизованому масштабі;
tyx1, t1, t2….tp – стандартизовані значення змінних.
Для визначення β- коефіцієнтів виходимо з принципу найкращого наближення розрахункових значень до вихідних даних, що лежить в основі методу найменших квадратів. Відсівається таке лінійне рівняння, щодо якого сума квадратів відхилень заданих значень ty, 1,2 …. p від розрахункових по рівнянню якнайменша з усіх можливих для рівнянь такого виду.
Ця вимога приводить до системи лінійних рівнянь щодо шуканих β-коефіцієнтів і називається системою нормальних рівнянь:
ry1 = β1 + r12 β2 +……+ r1p βp
ry2 = r2 1 β1 + β2+……+ r2p βp
................................................ (3.63)
ryp = rp1 β1 + rp2 β2 +…….+ βp.
Як видно, для отримання багатофакторного рівняння, крім "зовнішніх парних коефіцієнтів" кореляції між у і хi, тобто ry1, ry2 і т.д. вимагається знайти "внутрішні коефіцієнти" кореляції між чинниками-аргументами, тобто r12, r13…… r1р.
Правило складання системи нормальних рівнянь для відшукання β- коефіцієнтів формулюється таким чином: за коефіцієнти при невідомих β1, β2….. βр приймаються "внутрішні коефіцієнти" кореляції між чинниками-аргументами, а як вільні члени - "зовнішні коефіцієнти" кореляції між функцією і кожним з чинників.
Регресійну модель в більшості випадків розглядають як інструмент аналізу, планування і управління виробництвом. Звідси особливо строгі вимоги ставляться до надійності, адекватності й точності кожного коефіцієнта моделі. Якщо стандартна помилка знайденого коефіцієнта регресії перевершує його за абсолютною величиною, то не можна поручитися за достовірність не тільки того, на скільки одиниць свого найменування в середньому змінюється  при зміні Х на одиницю свого вимірювання, але і за напрям впливу даного чинника-аргументу.
при зміні Х на одиницю свого вимірювання, але і за напрям впливу даного чинника-аргументу.
Точність визначення коефіцієнтів множинної регресії суттєво залежить від ступеня стійкості системи нормальних рівнянь або, інакше, від ступеня обумовленості кореляційної матриці.
Система нормальних рівнянь є добре обумовленою, якщо малим змінам коефіцієнтів відповідають малі (того ж порядку) зміни рішень. Інакше кажучи, має місце безперервний зв'язок між коефіцієнтами системи рівнянь і її коренями - корені системи стійкі при малих змінах її коефіцієнтів.
Приклад. У табл. 3.5 наведена матриця коефіцієнтів кореляції собівартості перевезення пасажирів міським транспортом по трьох чинниках
Таблиця 3.5 – Матриця коефіцієнтів кореляції
| Х1 = tср. сут. | Х2 = Аср.сут. | Х3 = Пкм. | ry/xj | |||
| -0,8803 -0,7294 | -0,8803 0,9376 | -0,7294 0,9376 | -0,9108 0,9012 0,9055 | |||
При визначенні залежності собівартості перевезення пасажирів від Х1 і Х3, β-коефіцієнти знаходимо з вирішення системи нормальних рівнянь
β1 - 0,7294 β3 = -0,9108; (3.64)
-0,7294 β1 + β3 = 0,9055. (3.65)
Система має рішення
β1 = -0,5348, β3 = 0,5208. (3.66)
Якщо провести округлення всіх коефіцієнтів до десятих часток одиниці, отримаємо систему
β1 – 0,7 β3 = -0,9; (3.67)
-0,7 β1 - β3 = 0,9. (3.68)
Система має рішення
β1 = -0,5294, β3 = 0,5185. (3.69)
При цьому зміни коефіцієнтів:
∆а13 = -0,7294-(-0,7)= -0,0294; (3.70)
∆b1 = -0,9108-(-0,9)= -0,0108; (3.71)
∆b3 = 0,9055-0,9 = 0,055. (3.72)
І відповідні зміни коренів:
∆ β1 = -0,5348-(-0,5294)= -0,0054, (3.73)
∆ β3 = 0,5208-0,5185= 0,0023 (3.74)
того ж порядку; корені системи стійкі.
Проте існують системи, погано обумовлені, в яких малим змінам коефіцієнтів відповідають значні зміни рішень.
Приклад. Розглянемо систему нормальних рівнянь для визначення β- коефіцієнтів двофакторної моделі залежності собівартості перевезення пасажирів від Х1 і Х2, β- коефіцієнти знаходимо з вирішення системи нормальних рівнянь:
β1 – 0,8803 β2 = -0,9108; (3.75)
-0,8803 β1 + β2 = 0,9012. (3.76)
Система має рішення
β1 = -0,5219, β2 = 0,4418. (3.77)
Якщо провести округлення всіх коефіцієнтів до десятих часток одиниці, отримаємо систему
β1 – 0,9 β2 = -0,9; (3.78)
-0,9 β1 + β2 = 0,9. (3.79)
Система має рішення:
β1 = 0,4737, β2 = 0,4736. (3.80)
При цьому зміни коефіцієнтів
∆а12 = -0,8803-(-0,9)= -0,0119; (3.81)
∆b1 = -0,9108-(-0,9)= -0,0108; (3.82)
∆b2 = 0,9012-0,9= -0,001 (3.83)
і відповідні зміни коренів:
∆ β1 = -0,5219-(-0,4737)= -0,048; (3.84)
∆ β2 = 0,4418-0,4736= -0,0318. (3.85)
Зміна другого кореня перевищує його значення. Змінився навіть знак кореня. Крім того, отримане рішення значно перевищує зміни коефіцієнтів системи. Отже регресійна модель, побудована за допомогою β-коефіцієнтів, знайдених по цій матриці, виявилася б нестійкою і економічні висновки з неї б були неточні й ненадійні. Стійкість системи нормальних рівнянь є необхідною умовою надійності економіко-математичної моделі.
Особливо часто явище нестійкої системи має місце в моделях з великим числом параметрів, де проблема обумовленості має найважливіше значення.
Виявивши нестійкість системи нормальних рівнянь, треба знайти причину цього явища і можливість його усунення.
Звичайно погано обумовлена система нормальних рівнянь має місце за наявності тісних кореляційних зв'язків між аргументами, що включаються в модель.
Лінійна залежність деяких аргументах в генеральній сукупності інших називається мультиколінеарністю.
Якщо в генеральній сукупності два аргументи, наприклад Х1 и Х2 лінійно залежать один від одного, то система з Р невідомими зводиться до системи Р-1 невідомими. Така система Р рівнянь є невизначеною, а її матриця виродженою. За допомогою такої системи β- коефіцієнти не можуть бути однозначно визначеними. Отже, багатофакторна модель, що включає обидва аргументи Х1 и Х2, не може бути складеною.
Система рівнянь може виявитися погано обумовленою і її рішення будуть нестійкі, якщо в стовпцях або в рядках матриці розташовуються пропорційні значення "внутрішніх коефіцієнтів" кореляції між коефіцієнтами.
Явище мультиколінеарністі, тобто лінійна залежність одного з аргументу від інших виявляється декількома способами:
- професійними міркуваннями по суті досліджуваного явища;
- інструкцією заснованої на складанні "внутрішніх і "зовнішніх" коефіцієнтів" кореляції кожного з аргументів. Якщо "внутрішній коефіцієнт" кореляції більше "зовнішнього", то даний аргумент в рівняння множинної кореляції не слід включати;
- використанням статистичного критерію мультиколінеарністі (Феррара і Гюбера). Для цього розглядається величина
j = (Cij-1)  , (3.86)
, (3.86)
де Cij – діагональні елементи матриці, зворотної до кореляційної, знайденої за вибірковими даними;
n – обсяг вибірки;
p – число аргументів у рівнянні множинної регресії.
Зворотною по відношенню до даної називається матриця, яка, будучи помноженою як справа, так і зліва на дану матрицю, дає одиничну матрицю.
Для матриці А зворотна їй позначається через А-1. Тоді за визначенням маємо:
А-1*А = А* А-1 = Е (3.87)
Якщо існує зворотна матриця А-1, то матриця А називається зворотною. Для виродженої матриці зворотної матриці не існує, оскільки її визначник рівний нулю.
Визначник зворотної матриці рівний зворотній величині визначника даної матриці, що дає можливість обчислення зворотної матриці за допомогою визначників. Для цього використовуються поняття мінору і доповнення алгебри.
Мінором Мij елемента аij визначника Д=(Оij) називається такий новий визначник, який отриманий з даного визначника викреслюванням рядка і стовпця, що знаходиться через даний елемент матриці А.
Доповненням алгебри елемента аij визначника називається мінор Мij цього елемента, взятий зі знаком (-1). Доповнення алгебри елемента аij позначається через Аij. У прийнятому нами позначенні матимемо:
 (3.88)
(3.88)
Ферраром і Глобером доведено, що статична величина j підкоряється розподілу Фішера з (n-p) і (р-1) ступенями свободи. Отже, для виявлення мультиколінеарності використовується звичайний прийом перевірки статистичних гіпотез. Обчисливши вираз j (j=1,2…р), порівнюємо їх значення з табличними значеннями 5% и 1% при відповідних ступенях свободи [ (n-p) (p-10) ].
Якщо j < 5%, то гіпотеза відсутності мультиколінеарності j-го аргументу з іншими в генеральній сукупності стверджується. Навпаки, при j > 5% - відкидається гіпотеза відсутності мультиколінеарності j-го аргументу з іншими в генеральній сукупності. При 5% < j < 1% використовуються засоби послаблення мультиколінеарності шляхом переходу до нелінійних залежностей та ін.
Висновки про виключення якогось аргументу супроводяться логічним аналізом. По аргументах, що збереглися, повторюється перевірка мультиколінеарності.
Управління множинної регресії виявляється тим точніше і надійніше, чим слабше внутрішні кореляційні зв'язки між аргументами.
Знайдені в результаті рішення кореляційної матриці β- коефіцієнти показують на яку частину середньоквадратичного відхилення σу змінюється середнє значення функції, якщо відповідний аргумент зменшується або збільшується на юшок, а інші аргументи залишаються незмінними.
Найбільш доцільно відшукувати рівняння множинної регресії шляхом послідовного підключення до парного рівняння решти аргументів в порядку їх значущості (економічної, технологічної і т.п.). У цьому випадку виявляється можливість на кожному етапі аналізувати:
- обумовленість вирішуваної системи за чисельним значенням її визначника (детермінатора);
- зміна β- коефіцієнтів, чисельне значення яких має бути менше 1, а знак не суперечити логіці;
- зростання коефіцієнта множинної кореляції R і убування залишкової дисперсії 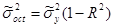 .
.
Методика послідовного підключення аргументів складається з наступних операцій.
1.Обирається аргумент Х1, якому відповідає найбільший за абсолютним значенням "зовнішній коефіцієнт" кореляції
| r y1| = max | r yi|, j = 1,2….q. (3.89)
За аргументом Х1 записується рівняння
ty1 = ty1 tx1. (3.90)
2. Приєднується аргумент Хio, для якого
| r xj X1 | = min | r xj x1 |, j = 2,3,… q. (3.91)
Складається система нормальних рівнянь
r yх1 = β1 + r хjo β2; (3.92)
r y xjo = β1 r хjo x1 + β2 (3.93)
і обчислюються значення β1 и β2. Визначаються
R2y, x1 хjo = β1 ryx1 + β2 r y xjo; (3.94)
σу, х1 xjo =  (3.95)
(3.95)
Порівнюється R2y, x1 хjo, σу, х1 xjo відповідно з r 2yx1, σу х1.
Переконуються в справедливості нерівності
R2y, x1 хjo ≥ r 2yx1 ; σу, xjo ≤ σу х1. (3.96)
У противному разі замінюється чинник аргумент іншим Xj1, а аргумент Xj0 переноситься на останнє місце.
3. Далі приєднується наступний аргумент Xj1 і розв'язується система з трьома невідомими:
r y х1 = β1 + β2 rх1 xjo + β3 rх1 xj1; (3.97)
r y xjo = β1 rх1 xjo + β2 + β3 r xjo xj1; (3.98)
r y xj1 = β1 rх1 xjo + β2 r xjo xj1 + β3. (3.99)
Обчислюються значення β1, β2 и β3. Визначаються
R2y, x1 хjo xj1 = β1 r y х1 + β2 r y xjo + β3 r y xj1; (3.100)
σу, xjo xj1 = σу  (3.101)
(3.101)
і порівнюються з R2y, x1 хjo і σу, x1 хjo. Переконуються в справедливості нерівності
R2y, x1 хjo xj1 ≥ R2y, x1 хjo; (3.102)
σу, x1 хjo xj1 ≤ σу, x1 хjo. (3.103)
У противному разі поступають аналогічно П.2.
Дослідження ведуть до тих пір, поки не будуть апробовані чинники-аргументи і збережені тільки ті з них, для яких βj–коефіцієнти суттєві й лінійно незалежні. У результаті виходить множинне рівняння в стандартизованому масштабі.
Від рівняння множинної регресії в стандартизованому масштабі
t xi = β1 t1 + β2 t2 + ….+ βp tn (3.104)
до рівняння множинної регресії в натуральному масштабі
х1, х2…Хр = а1х1 + а2х2 + ….+ архр +b. (3.105)
Перехід здійснюється подвійно.
1. Шляхом використання формул
 (3.106)
(3.106)
При цьому маємо
 (3.107)
(3.107)
Підставивши відомі значення , σxi, σу, βi і 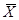 I, отримаємо рівняння множинної регресії в натуральному масштабі, в якому чисельне значення вільного члена додатково визначати не потрібно.
I, отримаємо рівняння множинної регресії в натуральному масштабі, в якому чисельне значення вільного члена додатково визначати не потрібно.
2. Невідомі коефіцієнти аi в рівнянні множинної регресії в натуральному масштабі визначають з виразу
 . (3.108)
. (3.108)
Чисельне значення вільного члена
b = -(а1 1+ а2 2 + …+ ар р). (3.109)
Для з'ясування математико-статистичного змісту множинної кореляції всю досліджувану групу змінних слід розглядати як один чинник-аргумент. Чисельне значення коефіцієнта множинної кореляції визначають за формулою
R= 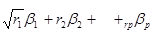 . (3.110)
. (3.110)
При цьому 0≤ R≤1. Коефіцієнт надійності
М =  . (3.111)
. (3.111)
Стандартну помилку (середню квадратичну похибку) коефіцієнта множинної кореляції визначають за формулою
σR = (1-R)/  , (3.112)
, (3.112)
де n-обсяг вибірки.
Сукупний вплив врахованих змінних на функцію визначається коефіцієнтом загальної детермінації R2, а окремих чинників-аргументів за чисельними значеннями приватної детермінації riβi:
R2 = r1β1 + r2β2+…..+ rpβp. (3.113)
Стандартну (систематичну) похибку  2 обчислюють за формулою
2 обчислюють за формулою
2 = 1-(1- R2)  , (3.114)
, (3.114)
де Р - число параметрів рівняння регресії. З рівняння множинної регресії можна отримати рівняння чистої (приватної) регресії по кожному з аргументу Xi. Для цього фіксується значення всіх аргументів, окрім Xi, на середньому рівні.
Отримане рівняння описує, як в середньому змінюється із зміною Xi, якщо всі інші аргументи постійні й закріплені саме на своїх середніх рівнях.
Приклад. Відповідно до наведеною методики скласти рівняння множинної регресії собівартості перевезення пасажирів від чинників: X1 – середньодобове перебування рухомого складу на лінії; X2 – середньодобова кількість пасажирів, що перевозяться, тис. чол.; X3 – пробіг рухомого складу на 1000 пасажирів, км, що перевозяться. Відомо, що = 78,9 коп., σу =3,5104, а в таблиці матриці наведені внутрішні й зовнішні коефіцієнти кореляції.
Таблиця 3.6 - Внутрішні й зовнішні коефіцієнти кореляції
| Х1 = t | X2 = 1/A | X3 = П | ryxi | i
| σxi | |
| t 1/A П | -0,8803 -0,7294 | -0,8803 0,9376 | -0,7294 0,9376 | -0,9108 0,9012 0,9055 | 11,757 0,0187 167,14 | 0,1611 0,00122 7,3996 |
Етап 1. Послідовно підключаються чинники-аргументи, в першу чергу з найбільшим "зовнішнім коефіцієнтом" кореляції і найменшим "внутрішнім". У нашому прикладі найбільше "зовнішні коефіцієнти" кореляції з мають Х1 и Х3.
Система нормальних рівнянь має вигляд
β1 – 0,7294 β3 = -0,9108; (3.115)
-0,7294 β1 + β3 = 0,9055. (3.116)
Отримане рішення
β1 = -0,5348 и β3 = 0,515. (3.117)
Визначаємо R2у, Х1 Х3 и σу,Х1Х3
R2у, Х1 Х3 = -0,9108 (-0,5348) + 0,9055 * 0,515 = 0,9534; (3.118)
σу,Х1Х3 = 3,51104  = 0,7578. (3.119)
= 0,7578. (3.119)
Порівнюємо R2у, Х1 Х3 і σу,Х1Х3 з r2yx, и σу,Х1, де справедливі рівняння 0,9534 >0,9108, 0,7578 < 3,5104.
Складаємо рівняння множинної регресії по двох чинниках-аргументах:
 = -0,5348
= -0,5348  + 0,515
+ 0,515  (3.120)
(3.120)
Після відповідних перетворень виходить рівняння множинної регресії собівартості по двох чинниках–аргументах, середньодобовому перебуванні рухомого складу на лінії і пробігу рухомого складу на 1000 перевезених пасажирів
 . (3.121)
. (3.121)
Етап 2. Приєднуємо наступний аргумент А- середньодобова кількість пасажирів, чол, що перевозяться. Складаємо систему нормальних рівнянь
 (3.122)
(3.122)
Обчислюємо  .
.
Рівняння множинної регресії по трьох чинниках–аргументах має вигляд:
 . (3.123)
. (3.123)
Після відповідних перетворень виходить управління множинної регресії пасажироперевезень по трьох чинниках – аргументах:
 (3.124)
(3.124)
Сукупний вплив облікових чинників на собівартість пасажироперевезень визначається загальною детермінацією, а окремих чинників аргументів за чисельними значеннями часткової детермінації  , які складають:
, які складають:

Отримані результати свідчать, що три чинники – аргументи, включені в множинну кореляційну залежність, на 92% обумовлюють собівартість пасажироперевезень міським електричним транспортом, у тому числі: середньодобове перебування рухомого складу на лінії - на 25,64%; середньодобова кількість пасажирів, що перевозяться - на 54,69%; пробіг рухомого складу на 1000 пасажирів, що перевозяться - на 11,93% при досить високому коефіцієнті кореляції R=0,9593.
Поиск по сайту: