АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Эволюция динамической памяти
Оперативная память - из глубин времен до наших дней
Крис Касперски
"Память определяет быстродействие"
Фон-Нейман
"Самый медленный верблюд определяет скорость каравана"
Арабское народное

Рисунок 1 Память… Миллиарды битовых ячеек, упакованных в крошечную керамическую пластинку, свободно умещающуюся на ладони…
Оперативная память персональных компьютеров сегодня, как и десять лет тому назад, строится на базе относительно недорогой динамической памяти - DRAM (D ynamic R andom A ccess M emory). Множество поколений интерфейсной логики, соединяющей ядро памяти с "внешним миром", сменилось за это время. Эволюция носила ярко выраженный преемственный характер - каждое новое поколение памяти практически полностью наследовало архитектуру предыдущего, включая, в том числе, и свойственные ему ограничения. Ядро же памяти (за исключением совершенствования проектных норм таких, например, как степень интеграции) и вовсе не претерпевало никаких принципиальных изменений! Даже "революционный" Rambus Direct RDRAM ничего подлинного революционного в себе не содержит и хорошо вписывается в общее "генеалогическое" древо развития памяти.
Поэтому, устройство и принципы функционирования оперативной памяти лучше всего изучать, понимаясь от основания ствола дерева (т.е. самых древних моделей памяти) по его веткам вверх - к самым современным разработкам, которые только существуют на момент написания этой статьи.
Устройство и принципы функционирования оперативной памяти
В ядре
Ядро микросхемы динамической памяти состоит из множества ячеек, каждая из которых хранит всего один бит информации. На физическом уровне ячейки объединяются в прямоугольную матрицу, горизонтальные линейки которой называются строками (ROW), а вертикальные - столбцами (Column) или страницами (Page).
Линейки представляют собой обыкновенные проводники, на пересечении которых находится "сердце" ячейки - несложное устройство, состоящее из одного транзистора и одного конденсатора (см. рис. 2.4).
Конденсатору отводится роль непосредственного хранителя информации. Правда, хранит он очень немного - всего один бит. Отсутствие заряда на обкладках соответствует логическому нулю, а его наличие - логической единице. Транзистор же играет роль "ключа", удерживающего конденсатор от разряда. В спокойном состоянии транзистор закрыт, но, стоит подать на соответствующую строку матрицы электрический сигнал, как спустя мгновение-другое (конкретное время зависит от конструктивных особенностей и качества изготовления микросхемы) он откроется, соединяя обкладку конденсатора с соответствующим ей столбцом.
Чувствительный усилитель (sense amp), подключенный к каждому из столбцов матрицы, реагируя на слабый поток электронов, устремившихся через открытые транзисторы с обкладок конденсаторов, считывает всю страницу целиком. Это обстоятельство настолько важно, что последняя фраза вполне заслуживает быть выделенной курсивом. Именно страница является минимальной порцией обмена с ядром динамической памяти. Чтение/запись отдельно взятой ячейки невозможно! Действительно, открытие одной строки приводит к открытию всех, подключенных к ней транзисторов, а, следовательно, - разряду закрепленных за этими транзисторами конденсаторов.
| "…эти шары содержат информацию… Их надо переписать на пленку, потому что они разового действия. Молекулы после прослушивания снова приходят в хаос" "Имею скафандр - готов путешествовать" Роберт Ханлайн |
Чтение ячейки деструктивно по своей природе, поскольку sense amp (чувствительный усилитель) разряжает конденсатор в процессе считывания его заряда. "Благодаря" этому динамическая память представляет собой память разового действия. Разумеется, такое положение дел никого устроить не может, и потому во избежание потери информации считанную строку приходится тут же перезаписывать вновь. В зависимости от конструктивных особенностей эту миссию выполняет либо программист, либо контроллер памяти, либо сама микросхема памяти. Практически все современные микросхемы принадлежат к последней категории. Редко какая из них поручает эту обязанность контроллеру, и уж совсем ни когда перезапись не возлагается на программиста.
Ввиду микроскопических размеров, а, следовательно, емкости конденсатора записанная на нем информация хранится крайне недолго, - буквально сотые, а то тысячные доли секунды. Причина тому - саморазряд конденсатора. Несмотря на использование высококачественных диэлектриков с огромным удельным сопротивлением, заряд стекает очень быстро, ведь количество электронов, накопленных конденсатором на обкладках, относительно невелико. Для борьбы с "забывчивостью" памяти прибегают к ее регенерации - периодическому считыванию ячеек с последующей перезаписью. В зависимости от конструктивных особенностей "регенератор" может находиться как в контроллере, так и в самой микросхеме памяти. Например, в компьютерах XT/AT регенерация оперативной памяти осуществлялась по таймерному прерыванию каждые 18 мс через специальный канал DMA (контроллера прямого доступа). И всякая попытка "замораживания" аппаратных прерываний на больший срок приводила к потере и/или искажению оперативных данных, что не очень-то радовало программистов, да к тому же снижало производительность системы, поскольку во время регенерации память была недоступна. Сегодня же регенератор чаще всего встраивается внутрь самой микросхемы, причем перед регенерацией содержимое обновляемой строки копируется в специальный буфер, что предотвращает блокировку доступа к информации.
Conventional DRAM (Page Mode DRAM) - "обычная" DRAM
Разобравшись с устройством и работой ядра памяти, перейдем к рассмотрению ее интерфейса. Физически микросхема памяти (не путать с модулями памяти) представляет собой прямоугольный кусок керамики (или пластика) "ощетинившийся" с двух (реже - с четырех) сторон множеством ножек. Что это за ножки?
В первую очередь выделим среди них линии адреса и линии данных. Линии адреса, как и следует из их названия, служат для выбора адреса ячейки памяти, а линии данных - для чтения и для записи ее содержимого. Необходимый режим работы определяется состоянием специального вывода W rite E nable (Разрешение Записи).
Низкий уровень сигнала WE готовит микросхему к считыванию состояния линий данных и записи полученной информации в соответствующую ячейку, а высокий, наоборот, заставляет считать содержимое ячейки и "выплюнуть" его значения в линии данных.
Такой трюк значительно сокращает количество выводов микросхемы, что в свою очередь уменьшает ее габариты. А, чем меньше габариты, тем выше предельно допустимая тактовая частота. Почему? Увы! В двух словах не расскажешь - тут замешен целый ряд физических явлений и эффектов. Во-первых, в силу ограниченной скорости распространения электричества, длины проводников, подведенных к различным ножкам микросхемы, должны не сильно отличаться друг от друга, иначе сигнал от одного вывода будет опережать сигнал от другого. Во-вторых, длины проводников не должны быть очень велики - в противном случае задержка распространения сигнала "съест" все быстродействие. В-третьих, любой проводник действует как приемная и как передающая антенна, причем уровень помех резко усиливается с ростом тактовой частоты. Паразитному антенному эффекту можно противостоять множеством способов (например, путем перекашивания сигналов в соседних разрядах), но самой радикальной мерой было и до сих пор остается сокращение количества проводников и уменьшение их длины. Наконец, в-четвертых, всякий проводник обладает электрической емкостью. А емкость и скорость передачи данных - несовместимы! Вот только один пример: "…первый трансатлантический кабель для телеграфа был успешно проложен в 1858 году,… когда напряжение прикладывалось к одному концу кабеля, оно не появлялось немедленно на другом конце и вместо скачкообразного нарастания достигало стабильного значения после некоторого периода времени. Когда снимали напряжение, напряжение приемного конца не падало резко, а медленно снижалось. Кабель вел себя как губка, накапливая электричество. Это свойство мы теперь называем емкостью"
Таким образом, совмещение выводов микросхемы увеличивает скорость обмена с памятью, но не позволяет осуществлять чтение и запись одновременно. (Забегая вперед, отметим, что, размещенные внутри кристалла процессора микросхемы кэш-памяти, благодаря своим микроскопическим размерам на количество ножек не скупятся и беспрепятственно считывают ячейку во время записи другой).
Столбцы и строки матрицы памяти тем же самым способом совмещаются в единых адресных линиях. В случае квадратной матрицы количество адресных линий сокращается вдвое, но и выбор конкретной ячейки памяти отнимает вдвое больше тактов, ведь номера столбца и строки приходится передавать последовательно. Причем, возникает неоднозначность, что именно в данный момент находится на адресной линии: номер строки или номер столбца? А, быть может, и вовсе не находится ничего? Решение этой проблемы потребовало двух дополнительных выводов, сигнализирующих о наличии столбца или строки на адресных линиях и окрещенных RAS (от row address strobe - строб адреса строки) и CAS (от column address strobe - строб адреса столбца) соответственно. В спокойном состоянии на обоих выводах поддерживается высокий уровень сигнала, что говорит микросхеме: никакой информации на адресных линиях нет и никаких действий предпринимать не требуется.
Но вот программист захотел прочесть содержимое некоторой ячейки памяти. Контроллер преобразует физический адрес в пару чисел - номер строки и номер столбца, а затем посылает первый из них на адресные линии. Дождавшись, когда сигнал стабилизируется, контроллер сбрасывает сигнал RAS в низкий уровень, сообщая микросхеме памяти о наличии информации на линии. Микросхема считывает этот адрес и подает на соответствующую строку матрицы электрический сигнал. Все транзисторы, подключенные к этой строке, открываются и бурный поток электронов, срываясь с насиженных обкладок конденсатора, устремляется на входы чувствительного усилителя. Чувствительный усилитель декодирует всю строку, преобразуя ее в последовательность нулей и единиц, и сохраняет полученную информацию в специальном буфере. Все это (в зависимости от конструктивных особенностей и качества изготовления микросхемы) занимает от двадцати до сотни наносекунд, в течение которых контроллер памяти выдерживает терпеливую паузу. Наконец, когда микросхема завершает чтение строки и вновь готова к приему информации, контроллер подает на адресные линии номер колонки и, дав сигналу стабилизироваться, сбрасывает CAS в низкое состояние. "Ага!", говорит микросхема и преобразует номер колонки в смещение ячейки внутри буфера. Остается всего лишь прочесть ее содержимое и выдать его на линии данных. Это занимает еще какое-то время, в течение которого контроллер ждет запрошенную информацию. На финальной стадии цикла обмена контроллер считывает состояние линий данных, дезактивирует сигналы RAS и CAS, устанавливая их в высокое состояние, а микросхема берет определенный тайм-аут на перезарядку внутренних цепей и восстановительную перезапись строки.
Задержка между подачей номера строки и номера столбца на техническом жаргоне называется " RAS to CAS delay " (на сухом официальном языке - tRCD). Задержка между подачей номера столбца и получением содержимого ячейки на выходе - " CAS delay " (или tCAC), а задержка между чтением последней ячейки и подачей номера новой строки - " RAS precharge " (tRP). Здесь и далее будут использоваться исключительно жаргонизмы - они более наглядны и к тому же созвучны соответствующим настойкам BIOS, что упрощает восприятие материала неподготовленными читателями.

Рисунок 2 Схематическое изображение модуля оперативной памяти (1); микросхемы памяти (2); матрицы (3) и отдельной ячейки памяти (4).
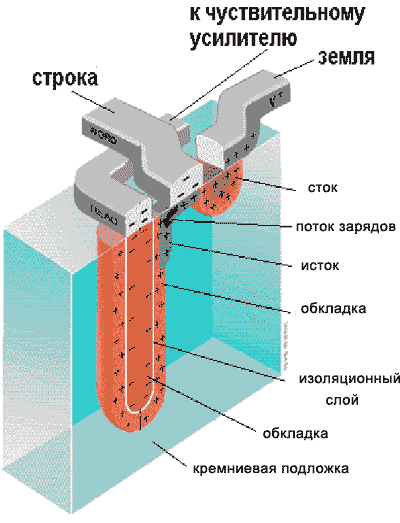
Рисунок 3 Устройство ячейки динамической памяти.
Эволюция динамической памяти.
В микросхемах памяти, выпускаемых вплоть до середины девяностых, все три задержки (RAS to CAS Delay, CAS Delay и RAS precharge) в сумме составляли порядка 200 нс., что соответствовало двум тактам в 10 мегагерцовой системе и, соответственно, двенадцати - в 60 мегагерцовой. С появлением Intel Pentium 60 (1993 год) и Intel 486DX4 100 (1994 год) возникла потребность в совершенствовании динамической памяти - прежнее быстродействие уже никого не устраивало.
FPM DRAM (Fast Page Mode DRAM)
быстрая страничная память
Первой ласточкой стала FPM-DRAM - F ast- P age M ode DRAM (Память быстрого страничного режима), разработанная в 1995 году. Основным отличием от памяти предыдущего поколения стала поддержка сокращенных адресо в. Если очередная запрашиваемая ячейка находится в той же самой строке, что и предыдущая, ее адрес однозначно определяется одним лишь номером столбца и передача номера строки уже не требуется. За счет чего это достигается? Обратимся к диаграмме, изображенной на рис.4. Смотрите, в то время как при работе с обычной DRAM (верхняя диаграмма) после считывания данных сигнал RAS дезактивируется, подготавливая микросхему к новому циклу обмена, контроллер FPM-DRAM удерживает RAS в низком состоянии, избавляясь от повторной пересылки номера строки.
При последовательном чтении ячеек памяти, (равно как и обработке компактных одно-двух килобайтовых структур данных), время доступа сокращается на 40%, а то и больше, ведь обрабатываемая строка находится во внутреннем буфере микросхемы, и обращаться к матрице памяти нет никакой необходимости!
Правда, хаотичное обращение к памяти, равно как и перекрестные запросы ячеек из различных страниц, со всей очевидностью не могут воспользоваться преимуществами передачи сокращенных адресов и работают с FPM-DRAM в режиме обычной DRAM. Если очередная запрашиваемая ячейка лежит вне текущей (так называемой, открытой) строки, контроллер вынужден дезактивировать RAS, выдержать паузу RAS precharge на перезарядку микросхемы, передать номер строки, выдержать паузу RAS to CAS delay и лишь затем он сможет приступить к передаче номера столбца.
Ситуация, когда запрашиваемая ячейка находится в открытой строке, называется "попаданием на страницу" (Page Hit), в противном случае говорят, что произошел промах (Page Miss). Поскольку, промах облагается штрафными задержками, критические к быстродействию модули должны разрабатываться с учетом особенностей архитектуры FPM-DRAM, так что абстрагироваться от ее устройства уже не получается.
Возникла и другая проблема: непостоянство времени доступа затрудняет измерение производительности микросхем памяти и сравнение их скоростных показателей друг с другом. В худшем случае обращение к ячейке составляет RAS to CAS Delay + CAS Delay + RAS precharge нс., а в лучшем: CAS Delay нс. Хаотичное, но не слишком интенсивное обращение к памяти (так, чтобы она успевала перезарядиться) требует не более RAS to CAS Delay + CAS Delay нс.
Поскольку, величины RAS to CAS Delay, CAS Delay и RAS precharge непосредственно не связаны друг с другом и в принципе могут принимать любые значения, достоверная оценка производительность микросхемы требует для своего выражения как минимум трех чисел. Однако производители микросхем в стремлении приукрасить реальные показатели, проводят только два: RAS to CAS Delay + CAS Delay и CAS Delay. Первое (называемое так же "временем [полного] доступа") характеризует время доступа к произвольной ячейке, а второе (называемое так же "временем рабочего цикла") - время доступа к последующим ячейкам уже открытой строки. Время, необходимое для регенерации микросхемы (т.е. RAS precharge) из полного времени доступа исключено. (Вообще-то, в технической документации, кстати, свободно доступной по Интернету, приводятся все значения и тайминги, так что никакого произвола в конечном счете нет).
Формула памяти
К середине девяностых среднее значение RAS to CAS Delay составляло порядка 30 нс., CAS Delay - 40 нс., а RAS precharge - менее 30 нс. (наносекунд). Таким образом, при частоте системной шины в 60 МГц (т.е. ~17 нс.) на открытие и доступ к первой ячейки страницы уходило около 6 тактов, а на доступ к остальным ячейкам открытой страницы - около 3 тактов. Схематически это записывается как 6-3-x-x и называется формулой памяти.
Формула памяти упрощает сравнение различных микросхем друг с другом, однако для сравнения необходимо знать преобладающий тип обращений к памяти: последовательный или хаотичный. Например, как узнать, что лучше: 5-4-x-x или 6-3-x-x? В данной постановке вопрос вообще лишен смысла. Лучше для чего? Для потоковых алгоритмов с последовательной обработкой данных, бесспорно, предпочтительнее последний тип памяти, в противном случае сравнение бессмысленно, т.к. чтение двух несмежных ячеек займет не 5-5-х-х и, соответственно, 6-6-х-х тактов, а 5+RAS precharge-5+RAS precharge-x-x и 6+RAS prechange-6+RAS prechange-x-x. Поскольку время регенерации обоих микросхем не обязательно должно совпадать, вполне может сложиться так, что микросхема 6-3-x-x окажется быстрее и для последовательного, и для хаотичного доступа. Поэтому, практическое значение имеет сравнение лишь вторых цифр - времени рабочего цикла. Совершенствуя ядро памяти, производители сократили его сначала до 35, а затем и до 30 нс., достигнув практически семикратного превосходства над микросхемами прошлого поколения.
EDO-DRAM (Extended Data Out)
память с усовершенствованным выходом
Между тем тактовые частоты микропроцессоров не стояли на месте, а стремительно росли, вплотную приближаясь к рубежу в 200 МГц. Рынок требовал качественного нового решения, а не изнуряющей борьбы за каждую наносекунду. Инженеров вновь отправили к чертежным доскам, где (году эдак в 1996) их осенила очередная идея. Если оснастить микросхему специальным триггером-защелкой, удерживающим линии данных после исчезновения сигнала CAS, станет возможным дезактивировать CAS до окончания чтения данных, подготавливая в это время микросхему к приему номера следующего столбца.
Взгляните на диаграмму рис. 4: видите, у FPM низкое состояние CAS удерживается до окончания считывания данных, затем CAS дезактивируется, выдерживается небольшая пауза на перезарядку внутренних цепей, и только после этого на адресную шину подается номер колонки следующей ячейки. В новом типе памяти, получившем название EDO-DRAM (Extend Data Output), напротив, CAS дезактивируется в процессе чтения данных параллельно с перезарядкой внутренних цепей, благодаря чему номер следующего столбца может подаваться до завершения считывания линий данных. Продолжительность рабочего цикла EDO-DRAM (в зависимости от качества микросхемы) составляла 30, 25 и 20 нс., что соответствовало всего двум тактам в 66 МГц системе. Совершенствование производственных технологий сократило и полное время доступа. На частоте 66 МГц формула лучших EDO-микросхем выглядела так: 5-2-x-x. Простой расчет позволяет установить, что пиковый прирост производительности (в сравнении с FPM-DRAM) составляет около 30%, однако, во многих компьютерных журналах тех лет фигурировала совершенно немыслимая цифра 50%, - якобы настолько увеличивалась скорость компьютера при переходе с FPM на EDO. Это могло быть лишь при сравнении худшей FMP-DRAM с самой "крутой" EDO-памятью, т.е. фактически сравнивались не технологии, а старые и новые микросхемы.
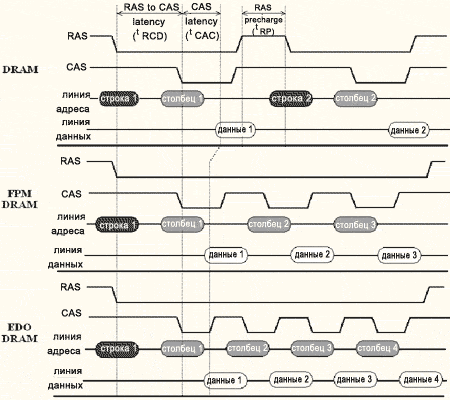
Рисунок 4 Временная диаграмма, иллюстрирующая работу некоторых типов памяти
Поиск по сайту: