АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Чтение записей с помощью индекса и их фильтрация
Схема операции (IndexScan + Filter) представлена на рис. 1.8.

Рис. 1.8. Чтение записей с помощью индекса.
Стоимость работы процессора и подсистемы ввода-вывода определяются следующими выражениями:
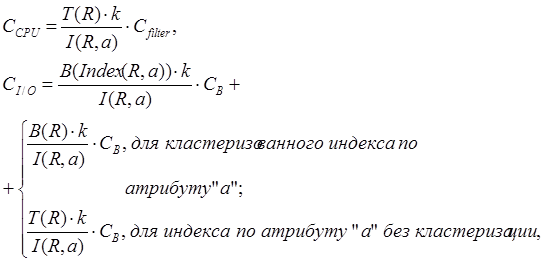 (5.5)
(5.5)
где
T(R) – число записей в таблице R;
B(R) – число блоков таблицы R;
I(R,a) – мощность атрибута "а" в таблице R (число различных значений);
B(Index(R,a)) – число блоков на листовом уровне индекса по атрибуту "а";
Сfilter – время фильтрации одной записи в ОП;
CB – время чтения/записи одного блока на диск;
k – мощность атрибута "а" в запросе (число различных значений, указанных в подзапросе φ).
Индекс по атрибуту является кластеризованным, если порядок записей в блоках таблицы такой же, как и в листовых блоках индекса.
Мощность атрибута в запросе (параметр k) можно оценить с помощью следующих выражений:
 (5.6)
(5.6)
Величину  в формулах (5.5) можно интерпретировать как вероятность, что запись таблицы R удовлетворяет условию φ по атрибуту "а".
в формулах (5.5) можно интерпретировать как вероятность, что запись таблицы R удовлетворяет условию φ по атрибуту "а".
Поиск по сайту: