АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Метод хешированного соединения (HJ – Hash Join)
При хешированном соединении выполняются следующие шаги:
1. Выбирается хеш-функция h(a).
2. Записи соединяемых таблиц хешируются, т.е. создаются хеш-разделы.
3. Выполняется соединение записей соответствующих разделов по алгоритму NLJ или SMJ.
Этот метод используется при условии равенства атрибутов соединения для очень больших соединяемых таблиц.
Пример двух таблиц, соединяемых методом хешированного соединения, приведён на рис. 1.20.
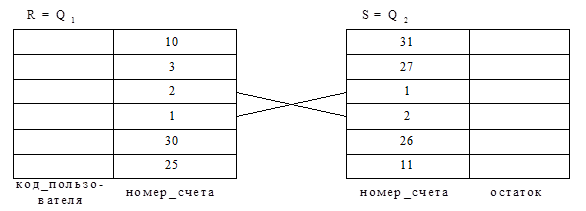
Рис. 1.20. Соединяемые таблицы.
1) В качестве хеш-функции выбрано деление номера счета по модулю 10.
2) Обозначим хеш-разделы следующим образом:
Ri – множество номеров счетов из R, у которых остаток от деления на 10 равен i;
Si – множество номеров счетов из S, у которых остаток от деления на 10 равен i.
3) Соединение разделов.
Представим процесс соединения в виде следующей таблицы (табл. 1.1).
Табл. 1.1.
Результаты соединения разделов
| Si Ri | S0=Ø | S1=(31, 1, 1) | S2=(2) | S3=Ø | S4=Ø | S5=Ø | S6=(26) | S7=(27) | S8=Ø | S9=Ø |
| R0=(10, 30) | – | |||||||||
| R1=(1) | ||||||||||
| R2=(2) | ||||||||||
| R3=(3) | – | |||||||||
| R4= Ø | – | |||||||||
| R5=(25) | – | |||||||||
| R6= Ø | – | |||||||||
| R7= Ø | – | |||||||||
| R8= Ø | – | |||||||||
| R9= Ø | – |
Соединение выполняется по диагонали, т.е. соединяются записи соответствующих разделов. При значительных объемах таблиц выигрыш бывает значительным, поскольку соединяются разделы, размеры которых намного меньше, чем размеры исходных таблиц.
Возможны два варианта реализации хешированного соединения.
1. Однопроходной вариант (рис. 1.21).
Все разделы Ri хранятся в оперативной памяти. Последовательно читаются блоки S с диска. Для каждой записи из S выполняется хеш-функция i=h(a) и значение атрибута соединения данной записи сравнивается со значениями атрибута соединения записей раздела Ri (для краткости будем говорить данная запись соединяется с записями раздела Ri).

Рис. 1.21. Распределение памяти в однопроходном варианте.
2. Двухпроходной вариант (рис. 1.22).
Таблицы R и S хешируются и их разделы {Ri} и {Si} сохраняются на диске. Далее в ОП читается весь раздел R0 и в буфер последовательно читаются блоки раздела S0. Их записи соединяются с записями раздела R0. Далее в оперативную память читается весь раздел R1 и далее S1 поблочно соединяется с R1 и т.д.
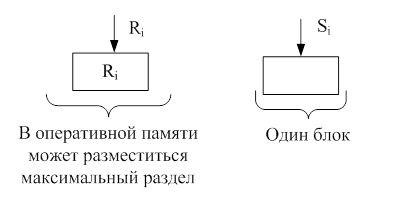
Рис. 1.22. Распределение памяти в двухпроходном варианте.
Теперь рассмотрим одну интересную особенность хешированного соединения.
В методах NLJ и SMJ соединяемые таблицы уже должны храниться на сервере перед выполнением соединения. В методе HJ соединение таблиц R и S может выполняться асинхронно, по мере поступления записей этих таблиц с других серверов (рис. 1.23).
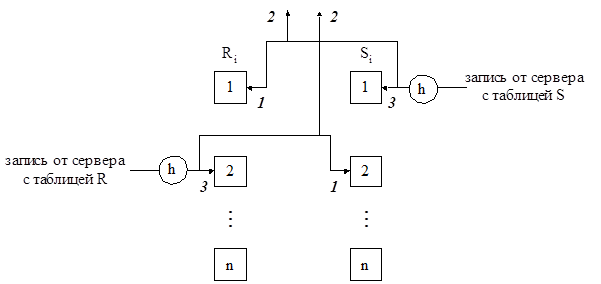
Рис. 1.23. Асинхронное соединение таблиц.
На рис. 1.23 цифрами обозначены следующие действия:
1 - сравнение поступившей записи с записями соответствующего противоположного раздела;
2 – вывод соединения двух записей при успешном сравнении атрибутов соединения;
3 – сохранение поступившей записи в соответствующем разделе.
Данная особенность позволяет существенно сократить время соединения таблиц.
Поиск по сайту: