АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Лекция 5. Логическое кодирование данных
В общем случае кодирование можно рассматривать как двухступенчатое: Кодирование- декодирование.
Логическое кодирование данных (data encoding) преобразует поток бит сформированного кадра в последовательность символов, подлежащих физическому кодированию для передачи по линии связи. Для логического кодирования используются разные схемы, из которых отметим следующие:
4В/5В — каждые 4 бита входного потока кодируются 5-битным символом (табл. 1.1). При этом получается двукратная избыточность, поскольку 24 = 16 входных комбинаций представляются символами из набора в 25 = 32. Накладные расходы по количеству битовых интервалов составляют (5-4)/4 = 1/4 (25%). Избыточность выходного кода позволяет определить ряд служебных символов, используемых для поддержания синхронизации, выделения служебных полей кадров и иных целей на физическом уровне. Применяется в FDDI(англ. Fiber Distributed Data Interface — Волоконно-оптический интерфейс передачи данных), 100BaseFX/TX.
8В/10В — похожая схема (8 бит кодируются 10-битным символом), но уже с 4-кратной избыточностью (256 входных в 1024 выходных) при том же уровне накладных расходов (25 %). Каждое из 256 возможных значений байта может быть представлено двумя вариантами выходных символов (позитивным и негативным), у которых не менее четырех нулей, не менее четырех единиц и не более четырех нулей или единиц подряд. Из пары вариантов выбирается тот, у которого первый бит отличается от последнего бита предыдущего переданного символа. Позволяет кроме данных по линии передавать и служебные символы (в них присутствуют последовательности из пяти нулей или единиц). Обеспечивает стабильное соотношение «нулей» и «единиц» в выходном потоке, не зависящее от входных данных. Это свойство актуально для лазерных оптических передатчиков — от данного соотношения зависит их нагрев, и при колебании степени нагрева увеличивается количество ошибок приема (обеспечивает вероятность ошибок 1 на 1012 бит). Применяется в 1000BaseSX/LX/CX.
5В/6В — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN. (В 100VG-AnyLAN Используется два уровня приоритетов: низкий — для обычных приложений и высокий — для мультимедийных. Арбитр доступа — концентратор. Летом 1995 года технология 100VG-AnyLAN получила статус стандарта, но не завоевала популярность среди производителей коммуникационного оборудования и к настоящему времени практически исчезла с рынка, разработка новых устройств не производится.)
8В/6Т — 8 бит входного потока кодируются шестью троичными (T=ternary) цифрами (-, 0, +). Например,
00h: +-00+-,
01h: 0+-+-0;
... 0Eh: -+0-0+;
... FEh: -+0+00;
FFh: +0-+00.
Код имеет избыточность 36/28 = 729/256 - 2,85, но скорость передачи символов в линию (правда, троичных) оказывается ниже битовой скорости их поступления на кодирование. Применяется в 100BaseT4.
Вставка бит (bit stuffing) — бит-ориентированная схема исключения недопустимых последовательностей бит. Входной поток рассматривается как непрерывная цепочка бит, для которой последовательность из более чем пяти смежных «1» рассматривается как служебный сигнал (например, 01111110 является флагом-разделителем кадра), Если в передаваемом потоке (заголовок кадра, пользовательские данные) встречается непрерывная цепочка «1», то после каждой пятой в выходной поток передатчик вставляет «0». Приемник анализирует Приходящую последовательность, и если после цепочки «011111» он принимает «0», то он его отбрасывает и цепочку «011111» присоединяет к выходному потоку данных. Если принят бит «1», то цепочка «0111111» уже рассматривается как элемент служебного символа.
На физическом уровне должна осуществляться синхронизация приемника и передатчика. Внешняя синхронизация — передача тактового сигнала, отмечающего битовые (символьные) интервалы, практически не применяется из-за дороговизны реализации дополнительного канала. Ряд схем физического кодирования являются само cамосинxpoнизирующиеся — они позволяют выделять синхросигнал из принимаемой последовательности состояний линии. Ряд схем позволяет выделять синхросигнал не для всех кодируемых символов, для таких схем логическое кодирование за счет избыточности должно исключать нежелательные комбинации.
Служебными символами логического кодирования 4В/5В:

- Символы состояния линии:
- Quiet, Q (kwaiэt молчание) - 00000;
- Idle, I (aidl простой) - 11111;
- Halt,I (ho:lt останов) - 00100.
Эти символы позволяют соседям по физическому соединению определить состояние соединения в процессе его инициализации и поддержания.
- Символы ограничителей начала и конца кадра:
- Start Delimiter 1 (первый символ границы начала кадра) - 11000;
- Start Delimiter 2 (второй символ границы начала кадра) - 10001;
- Ending Delimiter (конец кадра) - 01101.
Начало кадра отмечает встретившиеся подряд два символа Start Delimiter 1 и Start Delimiter 2, называемых также символами J и K (по аналогии со стандартом Token Ring). - Символы ограничителей начала и конца кадра:
- Reset (логический нуль) - 00111;
- Set (логическая единица) - 11001.
Эти символы используются для указания логических значений признаков распознавания адреса, ошибки и копирования кадра, имеющих в кадре FDDI назначение, аналогичное назначению соответствующих признаков кадра Token Ring.
В обязанности физического уровня входит фильтрация символов, передаваемых на выходную линию порта. Если среди символов кадра встречаются запрещенные символы, то они заменяются на 4 символа Halt, которые далее сопровождаются символами Idle до передачи следующего кадра. Последующий сосед, получив кадр с 4-мя символами Halt, должен изъять поврежденный кадр из кольца.
Осуществление синхронизации приемника с передатчиком в сети
FDDI при приеме кодов 4B/5В.
Во время этой процедуры для обмена информацией соседние порты используют не отдельные символы, а достаточно длинные последовательности символов, что повышает надежность взаимодействия. Эти последовательности называются состоянием линии. Всего используется 4 состояния линии:
· Quiet Line State, QLS - состояние молчания, состоит в передаче 16 или 17 символов Quiet подряд.
· Master Link State, MLS - состояние главного порта, состоит в передаче 8 или 9 пар символов Halt-Quiet.
· Halt Link State, HLS - состояние останова, состоит в передаче 16 или 17 символов Halt подряд.
· Idle Link State, ILS - состояние простоя, состоит в передаче 16 или 17 символов Idle подряд.
Первый этап инициализации заключается в передаче портом - инициатором соединения - состояния QLS соседнему порту. Тот должен при этом перейти в состояние BREAK - разрыва связи, независимо от того, в каком состоянии связь находилась до получения символов QLS. Соседний порт, перейдя в состояние BREAK, также посылает символы QLS, обозначая свой переход.
После того, как порт-инициатор убедился, что первый этап инициализации выполнен, он выполняет следующий этап - переход в состояние CONNECT (соединение). Делает он это посылкой символов HLS, на что соседний порт также должен ответить символами HLS.
Если состояние CONNECT установлено, то порт-инициатор начинает наиболее содержательный этап инициализации - NEXT, включающий обмен информацией о типе портов, проведение тестирования качества линии и проведение тестового обмена кадрами. Этап NEXT состоит в обмене между соседними портами 10-ю сообщениями, которые передаются по очереди. Порт передает одно свое сообщение, затем получает и анализирует сообщение от соседа и так далее. Каждое сообщение несет один бит информации и кодируется последовательностями MLS - логический ноль, или HLS - логическая единица.
Первые два сообщения несут информацию о типе своего порта (это особенность сетей работающих по FDDI). Третье сообщение говорит соседнему порту, приемлемо ли для данного порта соединение с указанным в принятых сообщениях типом порта. Если да, то следующие сообщения оговаривают длительность процедуры тестирования качества линии, а затем передают информацию о результатах тестирования. Тест состоит в передаче в течение определенного времени символов Idle и подсчете искаженных символов. Если качество линии приемлемо, то выполняется тестовый обмен кадрами данных.
Если все этапы инициализации прошли успешно, то физическое соединение считается установленным и активным. По нему начинают передаваться символы простоя и кадры данных. Однако, до тех пор, пока станция не выполнит процедуру логического соединения, кадры могут нести только служебную информацию.
«Контроль ошибок»
Мы рассмотрим три метода обнаружения ошибок в переданных данных: контроль четности (чтобы проиллюстрировать основные идеи, лежащие в основе методов обнаружения и исправления ошибок), вычисление контрольных сумм (этот метод больше характерен для транспортного уровня) и применение циклического избыточного кода (как правило, используется в адаптерах канального уровня).
Контроль четности. Возможно, простейшая форма обнаружения ошибок заключается в использовании одного бита четности. Предположим, что передаваемые данные D имеют длину d разрядов. При проверке на четность отправитель просто добавляет к данным один бит, значение которого вычисляется как сумма всех d разрядов данных по модулю 2. В этом случае количество единиц в получающемся в результате числе всегда будет четным. Применяются также схемы, в 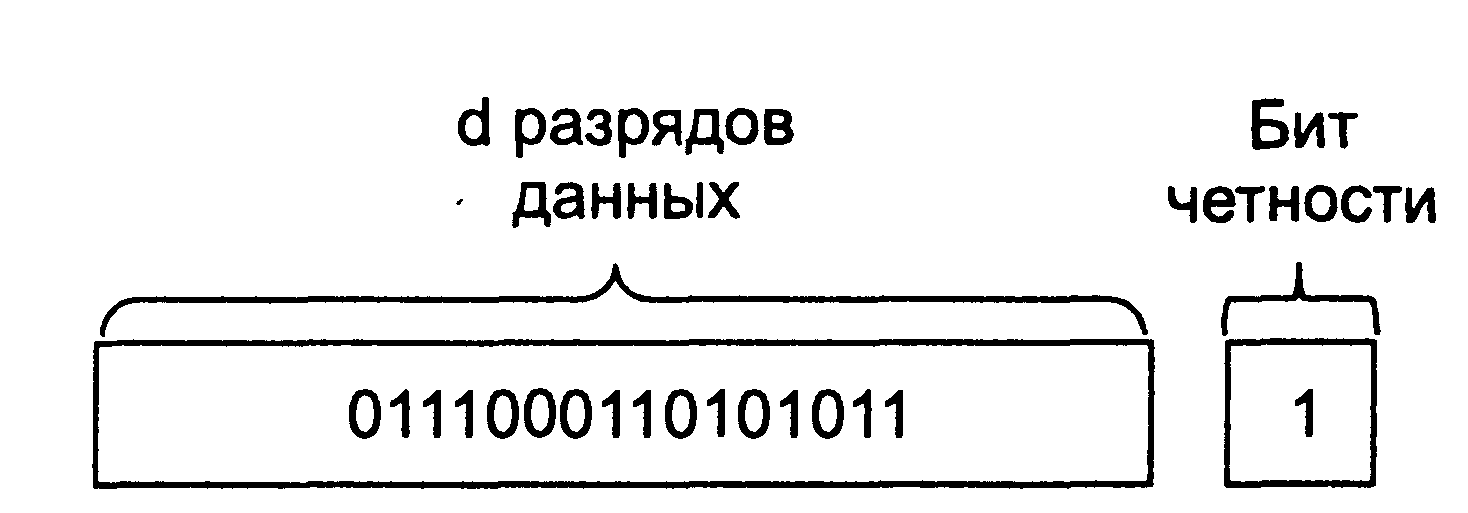 которых контрольный бит инвертируется, в результате чего количество единиц в получающемся в результате числе всегда будет нечетным.
которых контрольный бит инвертируется, в результате чего количество единиц в получающемся в результате числе всегда будет нечетным.
Действия, выполняемые получателем при использовании такой схемы, также очень просты. Получатель должен всего лишь сосчитать количество единиц в полученных d + 1 разрядах. Если при проверке на четность получатель обнаруживает, что в принятых им данных нечетное количество единичных разрядов, он понимает, что произошла ошибка, по меньшей мере, в одном разряде. Что произойдет, если в полученном пакете данных произойдет четное количество однобитовых ошибок? В этом случае получатель не сможет обнаружить ошибку.
Двухмерное обобщение одноразрядной схемы проверки на четность. В данной схеме d разрядов пакета данных разделяются на I строк и j столбцов, образуя прямоугольную матрицу. Значение четности вычисляется для каждой строки и каждого столбца. Получающиеся в результате I +J +1 битов четности образуют разряды обнаружения ошибок кадра канального уровня.


Предположим теперь, что в исходном блоке данных из d разрядов происходит однократная ошибка. В такой двухмерной схеме контроля четности об ошибке будут одновременно сигнализировать контрольные разряды строки и столбца. Таким образом, получатель сможет не только обнаружить сам факт ошибки, но и по номерам строки и столбца найти поврежденный бит данных и исправить его. Данная схема позволяет также обнаруживать и исправлять одиночные ошибки в самих битах четности
Метод вычисления контрольной суммы для пакетов требует относительно небольших накладных расходов. Например, в протоколах TCP и UDP для контрольной суммы используются всего 16 бит. Однако подобные методы предоставляют относительно слабую защиту от ошибок по сравнению с обсуждаемым далее методом контроля с помощью циклического избыточного кода, который часто используется на канальном уровне. Разумеется, возникает вопрос: почему на транспортном уровне применяют контрольные суммы, а на канальном уровне — циклический избыточный код? Вспомним, что транспортный уровень, как правило, реализуется на хосте программно как часть операционной системы хоста. Поскольку обнаружение ошибок на транспортном уровне реализовано программно, важно, чтобы схема обнаружения ошибок была простой. В то же время обнаружение ошибок на канальном уровне реализуется аппаратно в адаптерах, способных быстро выполнять более сложные операции по вычислению циклического избыточного кода.
Таким образом, основная причина использования контрольных сумм на транспортном уровне и более сложного метода вычисления циклического избыточного кода на канальном уровне состоит в том, что программно проще реализовать вычисление суммы.
Циклический избыточный код. Широко применяемый в современных компьютерных сетях метод обнаружения ошибок основан на контроле при помощи циклического избыточного кода (Cyclic Redundancy Check, CRC). Циклические избыточные коды также называют полиномиальными кодами, так как при их вычислении битовая строка рассматривается как многочлен (полином), коэффициенты которого равны 0 или 1, и операции с этой битовой строкой можно интерпретировать как операции деления и умножения многочленов.
Циклические коды работают следующим образом. Рассмотрим фрагмент данных D состоящий из d разрядов, которые передающий узел хочет отправить принимающему узлу. Отправитель и получатель должны договориться о последовательности из r + 1 бит, называемой образующим многочленом (или генератором), который мы будем обозначать G. Старший (самый левый) бит образующего многочлена G должен быть равен 1.

Для заданного фрагмента данных D отправитель формирует r дополнительных разрядов R, которые он добавляет к данным D так что получающееся в результате число, состоящее из d + r бит, делится по модулю 2 на образующий многочлен (число) G без остатка. Таким образом, процесс проверки данных на наличие ошибки относительно прост. Получатель делит полученные d + r бит на образующий многочлен G. Если остаток от деления не равен нулю, это означает, что данные повреждены. В противном случае данные считаются верными и принимаются.
Пример вычисления R для D = 101110, d = 6, G = 1001 и r = 3. В этом случае отправитель передает следующие 9 бит: 101110011.

Основными требованиями к полиному: его степень должна быть равна длине контрольной суммы в битах. При этом старший бит полинома обязательно должен быть равен “1”. В 32-разрядном стандарте CRC-32, принятом в ряде IEEE-протоколов канального уровня, используется образующий многочлен вида
GCRC-32 =100000100110000010001110110110111
или

Поиск по сайту: