АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Технології Data Mining
У ц ей час елементи штучного інтелекту активно впроваджуються в практичну діяльність менеджера. На відміну від традиційних систем штучного інтелекту, технологія інтелектуального пошуку й аналізу даних або "видобуток даних" (Data Mining - DM), не намагається моделювати природний інтелект, а підсилює його можливості потужністю сучасних обчислювальних серверів, пошукових систем і сховищ даних. Нерідко поруч зі словами "Data Mining" зустрічаються слова "виявлення знань у базах даних" (Knowledge Discovery in Databases).
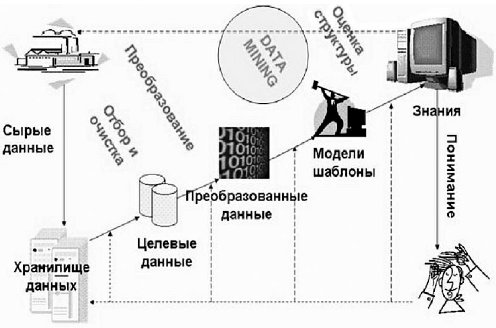
Рис. 2.7. Технологія Data Mining
Data Mining - це процес виявлення в сирих даних раніше невідомих, нетривіальних, практично корисні й доступні інтерпретації знань, необхідних для прийняття рішень у різних сферах людської діяльності. Data Mining являють більшу цінність для керівників і аналітиків у їхній повсякденній діяльності. Ділові люди усвідомили, що за допомогою методів Data Mining вони можуть одержати відчутні переваги в конкурентній боротьбі.
В основу сучасної технології Data Mining (Discovery-driven Data Mining) покладена концепція шаблонів (Patterns), що відбивають фрагменти багатоаспектних взаємин у даних. Ці шаблони являють собою закономірності, властиві вибіркам даних, які можуть бути компактно виражені в зрозумілої людині формі. Пошук шаблонів виробляється методами, не обмеженими рамками апріорних припущень про структуру вибірки й вид розподілів значень аналізованих показників. На рис. 2.7 показано схему перетворення даних з використанням технології Data Mining.

Рис. 2.8.Використання Data Mining
Основою для всіляких систем прогнозування служить історична інформація, що зберігається в БД у вигляді тимчасових рядів. Якщо вдається побудувати шаблони, що адекватно відбивають динаміку поводження цільових показників, є ймовірність, що з їхньою допомогою можна пророчити й поводження системи в майбутньому. На рис. 6.18 показано повний цикл застосування технології Data Mining.
Важливе положення Data Mining - нетривіальність розшукуваних шаблонів. Це означає, що знайдені шаблони повинні відбивати неочевидні, несподівані (Unexpected) регулярності в даних, складові так звані сховані знання (Hidden Knowledge). До ділових людей прийшло розуміння, що "сирі" дані (Raw Data) містять глибинний шар знань, і при грамотній його розкопці можуть бути виявлені справжні самородки, які можна використовувати в конкурентній боротьбі.
Сфера застосування Data Mining нічим не обмежена - технологію можна застосовувати всюди, де є величезні кількості яких-небудь "сирих" даних!
У першу чергу методи Data Mining зацікавили комерційні підприємства, що розгортають проекти на основі інформаційних сховищ даних (Data Warehousing). Досвід багатьох таких підприємств показує, що віддача від використання Data Mining може досягати 1000%. Відомі повідомлення про економічний ефект, в 10-70 разів превысившем первісні витрати від 350 до 750 тис. доларів. Є відомості про проект в 20 млн доларів, що окупився всього за 4 місяці. Інший приклад - річна економія 700 тис. доларів за рахунок впровадження Data Mining в одній з мереж універсамів у Великобританії.
Компанія Microsoft офіційно оголосила про посилення своєї активності в області Data Mining. Спеціальна дослідницька група Microsoft, очолювана Усамой Файядом, і шість запрошених партнерів (компанії Angoss, Datasage, Epiphany, SAS, Silicon Graphics, SPSS) готовлять спільний проект по розробці стандарту обміну даними й засобів для інтеграції інструментів Data Mining з базами й сховищами даних.
Data Mining є мультидисциплинарной областю, що виникла й розвивається на базі досягнень прикладної статистики, розпізнавання образів, методів штучного інтелекту, теорії баз даних і ін. (рис. 6.19).Звідси достаток методів і алгоритмів, реалізованих у різних діючих системах Data Mining. [Дюк В.А.. Багато хто з таких систем інтегрують у собі відразу кілька підходів. Проте, як правило, у кожній системі є якийсь ключовий компонент, на яку робиться головна ставка.
Можна назвати п'ять стандартних типів закономірностей, що виявляються за допомогою методів Data Mining: асоціація, послідовність, класифікація, кластеризация й прогнозування.

Рис. 2.9. Області застосування технології Data Mining
Асоціація має місце в тому випадку, якщо кілька подій зв'язані один з одним. Наприклад, дослідження, проведене в комп'ютерному супермаркеті, може показати, що 55% купивших комп'ютер беруть також і принтер або сканер, а при наявності знижки за такий комплект принтер здобувають в 80% випадків. Маючи відомості про подібну асоціацію, менеджерам легко оцінити, наскільки діюча надавана знижка.
Якщо існує ланцюжок зв'язаних у часі подій, то говорять про послідовність. Так, наприклад, після покупки будинку в 45% випадків протягом місяця здобувається й нова кухонна плита, а в межах двох тижнів 60% новоселів обзаводяться холодильником.
За допомогою класифікації виявляються ознаки, що характеризують групу, до якої належить той або інший об'єкт. Це робиться за допомогою аналізу вже класифікованих об'єктів і формулювання деякого набору правил.
Кластеризация відрізняється від класифікації тим, що самі групи заздалегідь не задані. За допомогою кластеризации засобу Data Mining самостійно виділяють різні однорідні групи даних.
Поиск по сайту: