АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Объектно-ориентированный подход к программированию
Основополагающей идеей объектно-ориентированного подхода является объединение данных и действий, производимых над этими данными, в единое целое, которое называется объектом. Функции объекта, называемые в C++ методами или функциями-членами, обычно предназначены для доступа к данным объекта. Если необходимо считать какие-либо данные объекта, нужно вызвать соответствующий метод, который выполнит считывание и возвратит требуемое значение. Прямой доступ к данным невозможен. Данные сокрыты от внешнего воздействия, что защищает их от случайного изменения. Говорят, что данные и методы инкапсулированы. Термины сокрытие и инкапсуляция данных являются ключевыми в описании объектно-ориентированных языков. Если необходимо изменить данные объекта, то, очевидно, это действие также будет возложено на методы объекта. Никакие другие функции не могут изменять данные класса. Такой подход облегчает написание, отладку и использование программы. Типичная программа на языке C++ состоит из совокупности объектов, взаимодействующих между собой посредством вызова методов друг друга. Структура программы на C++ приводится на рис. 1.3.

ООП: подход к организации программы. Объектно-ориентированное программирование никак не связано с процессом выполнения программы, а является лишь способом ее организации. Большая часть операторов C++ идентична операторам процедурных языков, в частности языка С. Внешне метод класса в C++ очень похож на обычную функцию языка C, и только по контексту программы можно определить, является ли функция частью процедурной С-программы или объектно-ориентированной программы на C++.
Рассмотрим несколько основных элементов, входящих в состав объект-но-ориентированных языков, в частности в состав языка C++.
Объекты. Когда вы подходите к решению задачи с помощью объектно-ориентированного метода, то вместо проблемы разбиения задачи на функции вы сталкиваетесь с проблемой разбиения ее на объекты. Что должно представляться в программе в виде объектов? Окончательный ответ может дать только ваше воображение: ♦ Физические объекты. ♦ Автомобили при моделировании уличного движения. ♦ Схемные элементы при моделировании цепи электрического тока. ♦ Страны при создании экономической модели. ♦ Самолеты при моделировании диспетчерской системы. ♦ Элементы интерфейса. ♦ Окна. ♦ Меню. ♦ Графические объекты (линии, прямоугольники, круги). ♦ Животные в играх, связанных с живой природой.
Классы. Практически все компьютерные языки имеют стандартные типы данных; например, в C++ есть целый тип int. Мы можем определять переменные таких типов в наших программах: int day; int a. Подобным же образом мы можем определять объекты класса.
Объекты этого класса
Object1 Object2 Object3
Таким образом, класс является описанием совокупности сходных между собой объектов. Объект класса часто также называют экземпляром класса.
4. Объектно-ориентированное программирование. Инкапсуляция (encapsulation). Иерархия классов. Наследование (inheritance). Полиморфизм (polymorphism).+3
Наследование. Понятие класса приводит нас к понятию наследования. В повседневной жизни мы часто сталкиваемся с разбиением классов на подклассы: например, класс животные можно разбить на подклассы млекопитающие, земноводные, насекомые, птицы и т. д. Принцип, положенный в основу такого деления, заключается в том, что каждый подкласс обладает свойствами, присущими тому классу, из которого выделен данный подкласс. Кроме тех свойств, которые являются общими у данных класса и подкласса, подкласс может обладать и собственными свойствами: например, автобусы имеют большое число посадочных мест для пассажиров, в то время как грузовики обладают значительным пространством и мощностью для перевозки тяжеловесных грузов и т. д. Иллюстрация этой идеи приведена на рис.

Подобно этому, в программировании класс также может породить множество подклассов. В C++ класс, который порождает все остальные классы, называется базовым классом, остальные классы наследуют его свойства, одновременно обладая собственными свойствами. Такие классы называются производными. Не проводите ложных аналогий между отношениями «объект—класс» и «базовый класс — производный класс»! Объекты, существующие в памяти компьютера, являются воплощением свойств, присущих классу, к которому они принадлежат. Производные классы имеют свойства как унаследованные от базового класса, так и свои собственные. Базовый класс содержит элементы, общие для группы производных классов. Роль наследования в ООП такая же, как и у функций в процедурном программировании, — сократить размер кода и упростить связи между элементами программы.
Повторное использование кода. Разработанный класс может быть использован в других программах. Это свойство называется возможностью повторного использования кода. Аналогичным свойством в процедурном программировании обладают библиотеки функций, которые можно включать в различные программные проекты. В ООП концепция наследования открывает новые возможности повторного использования кода. Программист может взять существующий класс, и, ничего не изменяя, добавить в него свои элементы. Все производные классы унаследуют эти изменения, и в то же время каждый из производных классов можно модифицировать отдельно.
Пользовательские типы данных. Одним из достоинств объектов является то, что они дают пользователю возможность создавать свои собственные типы данных. Представьте себе, что вам необходимо работать с объектами, имеющими две координаты, например x и y. Вам хотелось бы совершать обычные арифметические операции над такими объектами, например: position1 = position2 + origin где переменные position1, position2 и origin представляют собой наборы из двух координат. Описав класс, включающий в себя пару координат, и объявив объекты этого класса с именами position1, position2 и origin, мы фактически создадим новый тип данных. В C++ имеются средства, облегчающие создание подобных пользовательских типов данных.
Полиморфизм и перегрузка. Обратите внимание на то, что операции присваивания = и сложения + для типа position должны выполнять действия, отличающиеся от тех, которые они выполняют для объектов стандартных типов, например int. Объекты position1 и прочие не являются стандартными, поскольку определены пользователем как принадлежащие классу position. Как же операторы = и + распознают, какие действия необходимо совершить над операндами? Ответ на этот вопрос заключается в том, что мы сами можем задать эти действия, сделав нужные операторы методами класса position. Использование операций и функций различным образом в зависимости от того, с какими типами величин они работают, называется полиморфизмом. Когда существующая операция, например = или +, наделяется возможностью совершать действия над операндами нового типа, говорят, что такая операция является перегруженной. Перегрузка представляет собой частный случай полиморфизма и является важным инструментом ООП.
5. Язык С++. Типы данных. Диапазоны представления данных разных типов.
Концепция типа данных
Основная цель любой программы состоит в обработке данных. Данные различного типа хранятся и обрабатываются по-разному. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип.
Тип данных определяет:
внутреннее представление данных в памяти компьютера;
множество значений, которые могут принимать величины этого типа;
операции и функции, которые можно применять к величинам этого типа.
Исходя из этих характеристик, программист выбирает тип каждой величины, используемой в программе для представления реальных объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От выбора типа величины зависит последовательность машинных команд, построенная компилятором.
Все типы языка С++ можно разделить на простые (скалярные), составные (агрегатные) и функциональные. Простые типы могут быть стандартными и определенными программистом.
В языке С++ определено шесть стандартных простых типов данных для представления целых, вещественных, символьных и логических величин. На основе этих типов, а также массивов и указателей (указатель не является самостоятельным типом, он всегда связан с каким-либо другим конкретным типом), программист может вводить описание собственных простых или структурированных типов. К структурированным типам относятся перечисления, функции, структуры, объединения и классы.
Простые типы данных
Простые типы делятся на целочисленные типы и типы с плавающей точкой. Для описания стандартных типов определены следующие ключевые слова:
int (целый);
char (символьный);
wchar_t (расширенный символьный);
bool (логический);
float (вещественный);
double (вещественный с двойной точностью).
Существует четыре спецификатора типа, уточняющих внутреннее представление и диапазон значений стандартных типов:
short (короткий);
long (длинный);
signed (со знаком);
unsigned (без знака).
Целый тип (int)
Размер типа int стандартом ANSI не определяется. Он зависит от реализации. Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного — 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта. Спецификатор long означает, что целая величина будет занимать 4 байта.
Внутреннее представление величины целого типа — целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа.
По умолчанию все целочисленные типы считаются знаковыми.
Константам, встречающимся в программе, приписывается тип в соответствии с их видом. Программист может явно указать требуемый тип с помощью суффиксов L, l (long) и U, u (unsigned). Например, константа 32L имеет тип long и занимает 4 байта.
ПРИМЕЧАНИЕ
Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно.
Символьный тип (char)
Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера. Как правило, это 1 байт.
Тип char, как и другие целые типы, может быть со знаком или без знака.
В величинах со знаком можно хранить значения в диапазоне от –128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от 0 до 255. Величины типаchar применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short.
Логический тип (bool)
Величины логического типа могут принимать только значения true и false. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется какtrue. При преобразовании к целому типу true имеет значение 1.
Типы с плавающей точкой (float, double и longdouble)
Стандарт С++ определяет три типа данных для хранения вещественных значений: float, double и longdouble.
Внутреннее представление вещественного числа состоит из мантиссы и порядка. Длина мантиссы определяет точность числа, а длина порядка — его диапазон.
Константы с плавающей точкой имеют по умолчанию тип double. Можно явно указать тип константы с помощью суффиксов F, f (float) и L, l (long). Например, константа 2E+6L будет иметь тип long double.
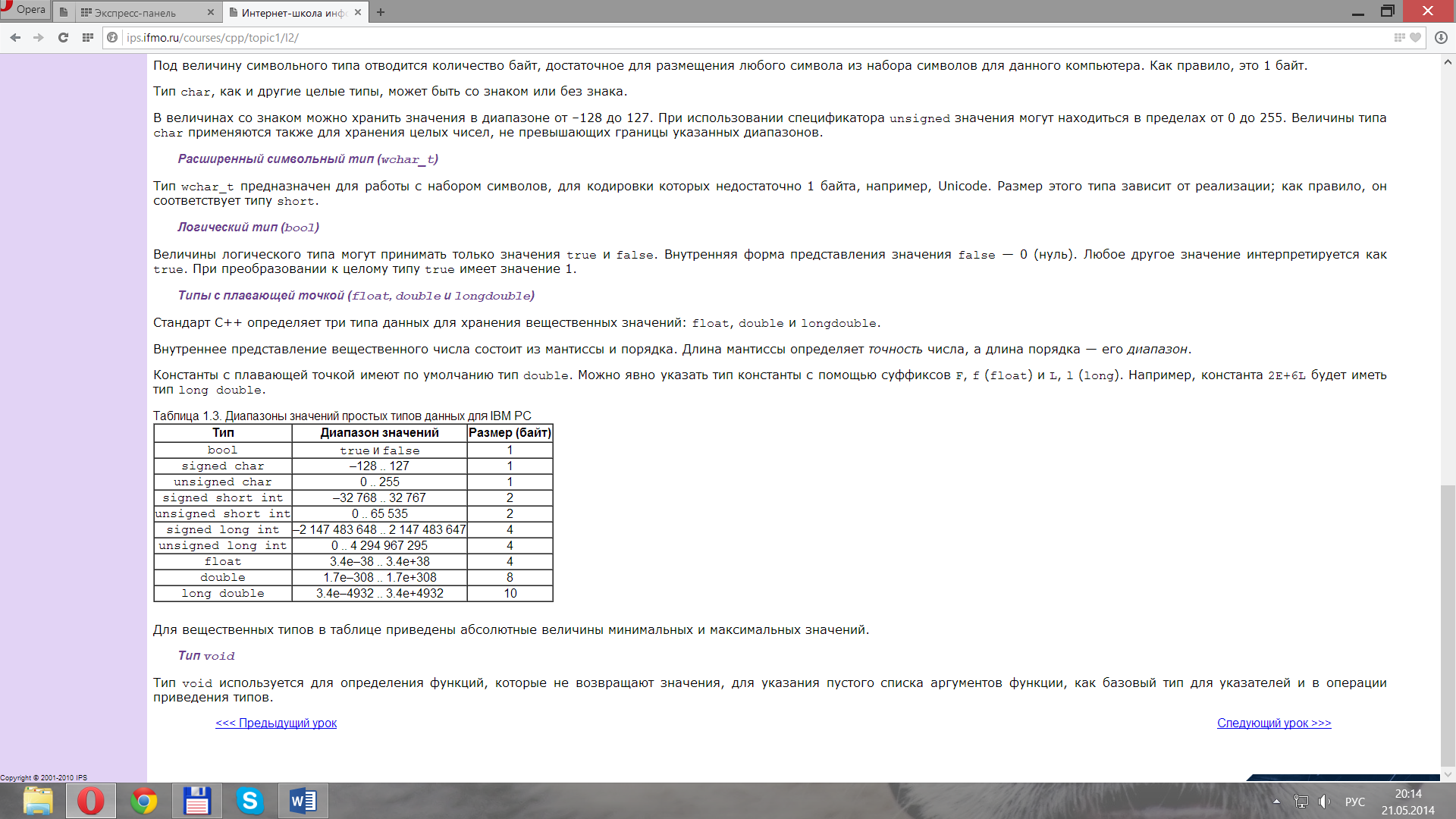
Для вещественных типов в таблице приведены абсолютные величины минимальных и максимальных значений.
Тип void
Тип void используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
6. Язык С++. Неявное преобразование данных.
Преобразования типов
Язык C++, как и его предшественник C, свободнее, чем многие другие языки программирования, обращается с выражениями, включающими в себя различные типы данных. В качестве примера рассмотрим программу MIXED:
// mixed.cpp
// использование смешанных выражений
#include <iostream> using namespace std;
int main()
{
int count = 7;
float avgWeight = 155.5F;
double totalWeight = count *avgWeight;
cout <<"Вес равен " << totalWeight << endl;
return 0;
}
Здесь переменная типа int умножается на переменную типа float, а результат присваивается переменной типа double. Компиляция программы происходит без ошибок, поскольку компиляторы допускают возможность перемножения (и выполнения других арифметических операций) с операндами разных типов. Не все языки поддерживают смешанные выражения, и некоторые из них фиксируют ошибки при попытке применить арифметические операции к данным разных типов. Такой подход предполагает, что подобные действия вызваны ошибкой программиста, и призван «сигнализировать» ему об этом. C и C++ предполагают, что смешивание типов данных произошло сознательно и является задумкой программиста, и поэтому не мешают ему реализовывать свои идеи. Подобный подход отчасти объясняет столь значительную популярность языков С и C++. Эти языки дают программисту большую свободу. Разумеется, подобная либеральность увеличивает вероятность допущения ошибок.
Неявные преобразования типов. Давайте рассмотрим действия компилятора, когда он встречает выражения со смешанными типами, подобные приведенным в программе MIXED. Каждый тип данных можно условно считать «ниже» или «выше» по отношению к другим типам. Иерархия типов данных приведена в табл. 2.4.

Арифметические операции, подобные + и *, действуют следующим образом: если их операнды имеют различные типы, то операнд с более «низким» типом будет преобразован к более «высокому» типу. Так, в программе MIXED тип int переменной count был преобразован в float с помощью введения временной переменной, содержимое которой умножается на переменную avgWeight. Результат, имеющий тип float, затем преобразовывается к типу double, чтобы его можно было присвоить переменной totalWeight. Процесс преобразования типов показан на рис. 2.9.
Подобные преобразования типов данных происходят неявно, и обычно нет необходимости задумываться над ними, поскольку C++ сам выполняет то, что мы хотим. Однако в ряде случаев компилятор не столь понятно проводит преобразования типов, и мы скоро в этом убедимся. Когда мы научимся работать с объектами, мы фактически будем оперировать собственными типами данных. Возможно, нам захочется применять переменные таких типов в смешанных выражениях, включающих в себя как стандартные, так и пользовательские типы данных. В этом случае нам самим придется создавать средства, выполняющие необходимые преобразования типов, поскольку компилятор не сможет преобразовывать пользовательские типы данных так, как он делал это со стандартными типами.
7. Язык С++. Явное преобразование данных.
Преобразования типов
Язык C++, как и его предшественник C, свободнее, чем многие другие языки программирования, обращается с выражениями, включающими в себя различные типы данных. В качестве примера рассмотрим программу MIXED:
// mixed.cpp
// использование смешанных выражений
#include <iostream> using namespace std;
int main()
{
int count = 7;
float avgWeight = 155.5F;
double totalWeight = count *avgWeight;
cout <<"Вес равен " << totalWeight << endl;
return 0;
}
Здесь переменная типа int умножается на переменную типа float, а результат присваивается переменной типа double. Компиляция программы происходит без ошибок, поскольку компиляторы допускают возможность перемножения (и выполнения других арифметических операций) с операндами разных типов. Не все языки поддерживают смешанные выражения, и некоторые из них фиксируют ошибки при попытке применить арифметические операции к данным разных типов. Такой подход предполагает, что подобные действия вызваны ошибкой программиста, и призван «сигнализировать» ему об этом. C и C++ предполагают, что смешивание типов данных произошло сознательно и является задумкой программиста, и поэтому не мешают ему реализовывать свои идеи. Подобный подход отчасти объясняет столь значительную популярность языков С и C++. Эти языки дают программисту большую свободу. Разумеется, подобная либеральность увеличивает вероятность допущения ошибок.
Явные преобразования типов. Явные преобразования типов, в отличие от неявных, совершаются самим программистом. Явные преобразования необходимы в тех случаях, когда компилятор не может безошибочно преобразовать типы автоматически. В C++ существует несколько различных операций приведения типов, однако здесь мы ограничимся рассмотрением лишь одной из них. Явные приведения типов в C++ ведут себя весьма требовательно. Вот пример оператора, осуществляющего преобразование типа int к типу char:
aCharVar = static_cast<char>(anIntVar);
Здесь переменная, тип которой мы хотим изменить, заключена в круглые скобки, а тип, к которому мы приводим переменную, — в угловые скобки. Приведение типа переменной anIntVar происходит перед присваиванием значения переменной aCharVar. Рассмотрим следующий пример.

Когда мы умножаем переменную intVar на 10, получаемый результат, равный 15 000 000 000, нельзя хранить, поскольку это приведет к получению неверного результата. Конечно, мы могли бы изменить тип данных на double, которого было бы достаточно для хранения нашего числа, поскольку тип double позволяет хранить числа длиной до 15 знаков. Но если мы не можем позволить себе подобный выход, например, из-за небольшого количества имеющейся в наличии памяти, то существует другой способ — привести переменную intVar перед умножением к типу double. Оператор
static_cast<double>(intVar)
создает временную переменную типа double, содержащую значение, равное значению intVar. Затем эта временная переменная умножается на 10, и поскольку результат также имеет тип double, переполнения не происходит. Затем временная переменная делится на 10, и результат присваивается обычной целой переменной intVar. Результат работы программы выглядит следующим образом:
Значение intVar равно 211509811
Значение intVar равно 1500000000
Первый из результатов, полученный без приведения типов, неверен; второй результат, являющийся результатом работы с приведением типов, оказывается правильным. До появления стандартного C++ приведение типов осуществлялось в несколько ином формате. Если сейчас оператор с приведением типов выглядит так:
aCharVar = static_cast <char>(anIntVar);
то раньше он записывался подобным образом:
aCharVar = (char)anIntVar;
или aCharVar = char(anIntVar);
Недостаток последних двух форматов заключается в том, что их трудно найти в листинге как визуально, так и с помощью команды поиска редактора кода. Формат, использующий static_cast, проще обнаружить как одним, так и другим способом. Несмотря на то, что старые способы приведения типа до сих пор поддерживаются компиляторами, их употребление не рекомендуется. Приведение типов следует использовать только в случае полной уверенности в его необходимости и понимания, для чего оно делается. Возможность приведения делает типы данных незащищенными от потенциальных ошибок, поскольку компилятор не может проконтролировать корректность действий при изменении типов данных. Но в некоторых случаях приведение типов оказывается совершенно необходимым, и мы убедимся в этом в наших будущих примерах.
8. Язык С++. Арифметические операции.
Арифметические операции. Как вы уже, вероятно, заметили, в языке C++ используются четыре основные арифметические операции: сложения, вычитания, умножения и деления, обозначаемые соответственно +, -, *, /. Эти операции применимы как к целым типам данных, так и к вещественным и их использование практически ничем не отличается ни от других языков программирования, ни от алгебры. Однако существуют также и другие арифметические операции, использование которых не столь очевидно.
Остаток от деления. Существует еще одна арифметическая операция, которая применяется только к целым числам типа char, short, int и long. Эта операция называется операцией остатка от деления и обозначается знаком процента %. Результатом этой операции, иногда также называемой «взятием по модулю», является остаток, получаемый при делении ее левого операнда на правый. Программа REMAIND демонстрирует применение этой операции.

В этой программе берутся остатки от деления чисел 6, 7, 8, 9 и 10 на 8, а результаты — 6, 7, 0, 1 и 2 — выводятся на экран. Операция остатка от деления используется довольно широко, и она еще понадобится нам в других программах. Заметим, что в операторе
cout << 6 % 8
операция остатка от деления выполняется раньше, чем операция <<, поскольку приоритет последней ниже. Если бы это было не так, то мы были бы вынуждены заключить операцию 6 % 8 в скобки, чтобы выполнить ее до посылки в поток вывода.
Арифметические операции с присваиванием. Язык C++ располагает средствами для того, чтобы сократить размер кода и сделать его наглядным. Одним из таких средств являются арифметические операции с присваиванием. Они помогают придать характерный вид программному коду в стиле C++. В большинстве языков программирования типичным является оператор, подобный
total = total + item; // сложение total и item
В данном случае вы производите сложение с замещением уже существующего значения одного из слагаемых. Но такая форма оператора не отличается краткостью, поскольку нам приходится дважды использовать в нем имя total. В C++ существует способ сократить подобные операторы, применяя арифметические операции с присваиванием. Такие операции комбинируют арифметическую операцию и операцию присваивания, тем самым исключая необходимость использования имени переменной дважды. Предыдущий оператор можно записать с помощью сложения с присваиванием следующим образом:
total += item; // сложение total и item
С присваиванием комбинируется не только операция сложения, но и другие арифметические операции: -=, *=, /=, %= и т. д. Следующий пример демонстрирует использование арифметических операций с присваиванием:

Использовать арифметические операции с присваиванием при программировании не обязательно, но они являются довольно употребительными в C++, и мы будем пользоваться ими в других наших примерах.
Инкремент. Операция, которую мы сейчас рассмотрим, является более специфичной, нежели предыдущие. При программировании вам часто приходится иметь дело с увеличением какой-либо величины на единицу. Это можно сделать «в лоб», используя оператор
count = count + 1; //увеличение count на 1
или с помощью сложения с присваиванием:
count += 1; //увеличение count на 1
Но есть еще один, более сжатый, чем предыдущие, способ:
++count; //увеличение count на 1
Операция ++ инкрементирует, или увеличивает на 1, свой операнд.
Префиксная и постфиксная формы. Знак операции инкремента может быть записан двояко: в префиксной форме, когда он расположен перед своим операндом, и в постфиксной форме, когда операнд записан перед знаком ++.
В чем разница? Часто инкрементирование переменной производится совместно с другими операциями над ней:
totalWeight = avgWeight * ++count;
Возникает вопрос — что выполняется раньше: инкрементирование или умножение? В данном случае первым выполняется инкрементирование. Каким образом это определить? Префиксная форма записи и означает то, что инкремент будет выполнен первым. Если бы использовалась постфиксная форма, то сначала бы выполнилось умножение, а затем переменная count была бы увеличена на 1.
Декремент. Операция декремента, обозначаемая --, в отличие от операции инкремента, уменьшает, а не увеличивает, на единицу свой операнд. Декремент также допускает префиксную и постфиксную формы записи.
Библиотечные функции. Многие действия языка C++ производятся с помощью библиотечных функций. Эти функции обеспечивают доступ к файлам, производят математические расчеты, выполняют преобразование данных и множество других действий. Информацию о них можно получить с помощью справочной системы вашего компилятора, содержащей описания сотен библиотечных функций (sqrt()).
9. Язык С++. Логические операции.
Логические операции. До сих пор мы использовали только два типа операций (если не считать условную операцию): арифметические операции (+, -, *, / и %) и операции отношения (<, >, <=, >=, == и!=). Теперь мы рассмотрим третью группу операций, называемых логическими операциями. Эти операции позволяют производить действия над булевыми переменными, то есть переменными, обладающими только двумя значе ниями — истина и ложь. Так, например, высказывание «Сегодня рабочий день» имеет булево значение, поскольку оно может быть только истинным или ложным. Другим примером булева выражения является высказывание «Мария поехала на автомобиле». Мы можем логически связать эти два высказывания: «если сегодня рабочий день и Мария поехала на автомобиле, то я должен воспользоваться автобусом». Логическая связь в данном примере устанавливается с помощью соединительного союза и, который определяет истинность или ложность комбинации двух соединяемых высказываний. Только в том случае, если оба высказывания являются истинными, я буду вынужден воспользоваться автобусом.
Операция логического И. Давайте рассмотрим, каким образом логические операции соединяют булевы выражения в C++. В следующем примере, ADVENAND, логическая операция используется для усложнения приключенческой игры, созданной в программе ADSWITCH. Теперь мы закопаем сокровище в точке с координатами (7, 11) и попробуем заста- вить нашего героя отыскать его.

Ключевым моментом данной программы является выражение
if (x==7 && y==11)
Условие, участвующее в этом выражении, будет истинным только в том случае, когда значение x будет равно 7, а значение у в это же время окажется равным 11.
Операция логического И, обозначаемая &&, связывает пару относительных выражений (под относительным выражением понимается выражение, содержащее операции отношения). Обратите внимание на то, что использование скобок, заключающих относи- тельные выражения, не является обязательным:
((x==7 && y==11)) // внутренние скобки не обязательны
Это объясняется тем, что операции отношения имеют более высокий приоритет, чем логические операции. Если игрок попадет в точку, где находится сокровище, программа отреагирует на это следующим образом:
Ваши координаты: 7, 10
Выберите направление (n, s, е, w): s
Вы нашли сокровище!
В C++ существуют 3 логические операции:

Операция «исключающее ИЛИ» в языке C++ отсутствует.
Логическое ИЛИ.
Логическое НЕ. Операция логического НЕ является унарной, то есть имеет только один операнд (почти все операции C++, которые мы рассматривали, являлись бинарными, то есть имели два операнда; условная операция служит примером тернарной операции, поскольку имеет три операнда). Действие операции! заключается в том, что она меняет значение своего операнда на противоположное: если операнд имел истинное значение, то после применения операции! он становится ложным, и наоборот. Например, выражение (x==7) является истинным, если значение x равно 7, а выражение!(x==7) является истинным для всех значений x, которые не равны 7 (в данной ситуации последнее выражение эквивалентно записи x!=7).
Целые величины в качестве булевых. Из всего вышесказанного у вас могло сложиться впечатление, что для того, чтобы выражение имело истинное или ложное значение, необходимо, чтобы это выражение включало в себя операцию отношения. На самом деле любое выражение целого типа можно рассматривать как истинное или ложное, даже если это выражение является обычной переменной. Пример. Таким образом, применяя операцию остатка от деления, можно записать условие, определяющее местоположение грибов: if (x%7==0 && у%7==0) cout << "Здесь находится гриб.\n";
10. Язык С++. Операции отношений.
Операции отношения. Операция отношения сравнивает между собой два значения. Значения могут быть как стандартных типов языка C++, например char, int или float, так и типов, определяемых пользователем. Сравнение устанавливает одно из трех возможных отношений между переменными: равенство, больше или меньше. Результатом сравнения является значение истина или ложь. Например, две величины могут быть равны (истина) или не равны (ложь).
Наш первый пример RELAT демонстрирует использование операций сравнения применительно к целым переменным и константам.

Эта программа использует три вида сравнения числа 10 с числом, вводимым пользователем. Если пользователь введет значение, равное 20, то результат работы программы будет выглядеть так:
Первое выражение истинно в том случае, если значение numb меньше, чем 10; второе — тогда, когда numb больше, чем 10; и наконец, третье — когда numb равно 10.
Как можно видеть из результата работы программы, компилятор C++ присваивает истинному выражению значение 1, а ложному — значение 0.
Стандартный C++ включает в себя тип bool, переменные которого имеют всего два значения: true и false. Возможно, вы подумали о том, что результаты сравнения выражений должны иметь тип bool, и, следовательно, программа должна выводить false вместо 0 и true вместо 1, но C++ интерпретирует true и false именно как 1 и 0. Это отчасти объясняется историческими причинами, поскольку в языке C не было типа bool, и наиболее приемлемым способом представить ложь и истину представлялись именно числа 0 и 1. С введением типа bool два способа интерпретации истинности и ложности объединились, и их можно представлять как значениями true и false, так и значениями 1 и 0. В большинстве случаев не важно, каким из способов пользоваться, поскольку нам чаще приходится использовать сравнения для организации циклов и ветвлений, чем выводить их результаты на экран. Полный список операций отношения в C++ приводится ниже.

Теперь рассмотрим выражения, использующие операции сравнения, и значения, получающиеся в результате вычисления таких выражений. В первых двух строках примера, приведенного ниже, присваиваются значения переменным harry и jane. Далее вы можете, закрыв комментарии справа, проверить свое умение определять истинность выражений.

Обратите внимание на то, что операция равенства, в отличие от операции присваивания, обозначается с помощью двойного знака равенства. Распространенной ошибкой является употребление одного знака равенства вместо двух. Подобную ошибку трудно распознать, поскольку компилятор не увидит ничего неправильного в использовании операции присваивания. Разумеется, эффект от работы такой программы, скорее всего, будет отличаться от желаемого.
Несмотря на то, что C++ использует 1 для представления истинного значения, любое отличное от нуля число будет воспринято им как истинное. Поэтому истинным будет считаться и последнее выражение в нашем примере.
Поиск по сайту: