АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Международный стандарт Unicode
В 90-х гг. появился международный стандарт Unicode, который использует для кодирования кода символа два байта, и поэтому с его помощью можно закодировать 65 536 различных символов (216), т. е. представить знаки практически всех языков, имеющих письменность. В документах Unicode можно встретить одновременно китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы. Стандарт был разработан некоммерческой организацией «Консорциум Юникода» (англ. Unicode® Consortium, Unicode Inc., созданная в 1991 году), которая занимается его развитием.
Данный стандарт поддерживается практически всеми операционными системами, а также всеми современными браузерами. Он включает символы всех европейских языков, большинства азиатских языков и языков Ближнего Востока (с написанием слов справа налево). Кроме того, в стандарт входят знаки пунктуации, диакритические знаки (например, тильда ~ для выделения акцентированных букв, как ñ), математические знаки, специальные символы, стрелки, полиграфические символы и т. д. В Unicode также имеется набор свободных кодов, которые могут быть использованы компаниями или пользователями для представления своих собственных символов.
Для стандарта Unicode имеется три формы представления (Unicode transformation format, UTF), которые позволяют одни и те же данные закодировать одним байтом, двумя байтами или удвоенным машинным словом (4 байта). Это соответственно 8, 16 или 32 бита на один символ. Преобразование из одной формы представления в другую возможно без потерь данных.
 Преимуществом UTF-8 является то, что эта форма совместима с системами, использующими 8-битные символы, например ASCII. В тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
Преимуществом UTF-8 является то, что эта форма совместима с системами, использующими 8-битные символы, например ASCII. В тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
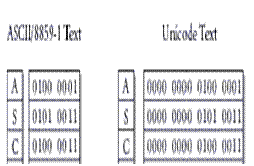
Коды в стандарте Unicode разделены на несколько областей (коды записываются в шестнадцатиричной системе счисления). Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами (рис. 1). Далее расположены области знаков различных письменностей, знаки пунктуации и специальные символы. Под символы кириллицы выделены коды от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
В Unicode символы, имеющие дополнительные над- или подстрочные элементы (диакритические знаки), могут быть представлены в виде последовательности кодов (составной вариант, composite character) или в виде единого символа (precomposed character). Например, буква немецкого алфавита "ü" может быть представлена единым кодом U+00FC "ü" или в виде сочетания базового символа U+0075 "u" и диакритического знака U+0308 "¨".
Поиск по сайту: