АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Пакет статистических программ Statistica
Данная система задумывалась как полная статистическая система для пользователей персональных компьютеров, не привыкших к работающим в пакетном режиме ранних версий других статистических пакетов SAS или SPSS. С самого начала эта программа обладала развитым графическим интерфейсом и опиралась на поддержку высококачественной графики для анализа данных.
Система состоит из ряда модулей, работающих независимо. Это означает, что все методы статистической обработки, реализованные в системе, разбиты на несколько групп модулей, в соответствии с разделами статистического анализа. Например, модуль Basic Statistica and Tables (Основные статистики и таблицы) содержит основные описательные статистики, методы статистического анализа различных таблиц, разносторонний инструментарий для проведения разведочного анализа данных. Имеется Multiple Regression (Многомерная регрессия), ANOVA (Дисперсионный анализ), Nonparametrics (Непараметрические статистики), Распределения (Distribution Fitting) и многие другие. Графики в данной системе строятся как из общего меню, так и из подменю процедур, что очень облегчает начинающим выбор адекватного графического представления данных.
Почти все процедуры являются интерактивными, т.е. для запуска обработки необходимо выбрать из меню переменные и ответить на ряд вопросов системы. Это очень удобно для начинающего пользователя, однако резко замедляет деятельность опытного и не позволяет эффективно повторять одну и ту же процедуру несколько раз.
Пакет Statisticaявляется наиболее динамично развивающимся статистическим пакетом и по многочисленным рейтингам является мировым лидером на рынке статистического программного обеспечения.
Знакомство с интерфейсом программы. Меню типа File (Файл), Edit (Правка), Window (Окно), Help (Справка), стандартны для любых приложений Windows и не вызовут сложностей. Основные файлы пакета имеют расширение *.sta.
Создание файла. В меню Файл (File) выберите Новый (New). Выбрать 10×10. ОК. Данные в программе Statistica представлены электронной таблицей. Все столбцы называются Переменные (Variables), сокращённо Var 1, Var 2, Var 3 и т.п. Все строки называются Наблюдения (Cases), обозначены простыми арабскими цифрами. Изменение количества строк или столбцов. Для увеличения количества строк нажмите кнопку Наблюдения (Cases) и, из предлагаемого меню, выберите функцию Добавить (Add). В возникшем окне измените Число наблюдений (How many) на 1, а Вставить после (Insert after case) на 10. Нажмите OK. Мы получим добавление одной строки после 10-ой. Для увеличения количества столбцов используйте кнопку Переменные (Vars). Аналогично выбрав функцию Добавить (Add) измените Число переменных (How many) на 1, а Вставить после (After) на 10. Нажав OK, мы получим добавление одного столбца после 10-ого.
Для того чтобы изменить имя столбца или строки подведите курсор к ячейке с именем и произведите на ней двойной щелчок мыши. В появившемся окне, в ячейке Имя (Name) наберите название ячейки и нажмите OK.
Описательные статистики. Создайте таблицу:
| Уровень | Частота | |
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 |
Найдите меню Статистических модулей (Statistics). Выберите функцию Основные статистики и таблицы (Basic Statistics/Tables). Нажмите OK. В проявившемся списке найдите Описательные статистики (Descriptive Statistics) и нажмите OK. В окне найдите кнопку Переменные (Variables). В новом окне выберите переменную Уровень. Нажмите ОК. Вернувшись в предыдущее окно, нажмите кнопку В (W). Должно появиться окно Задание веса (Analysis/Graph Case Weights). Двойным щелчком мыши вызовите в графе Вес из переменной (Weight variable) новое окно. В нём выберите переменную Частота. Нажмите ОК. Вернувшись в окно Задание веса (Analysis/Graph Case Weights), нажмите ОК.
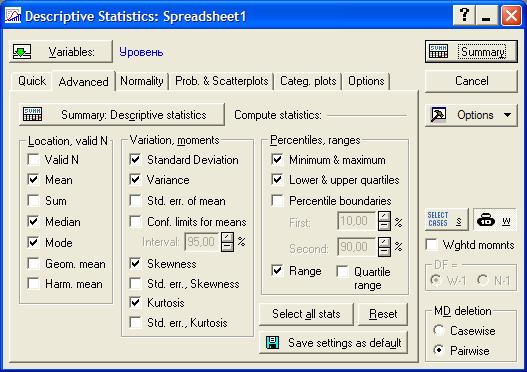
Во вкладке Advanced выберите следующие показатели: Минимум и максимум (Minimum & maximum), Верхняя и нижняя квартили (Lower and upper quartiles), Среднее (Mean), Выборочная дисперсия (Variance), Медиана (Median), Мода (Mode), Range (Размах), Стандартное отклонение (Standard Deviation), Skewness (Выборочный коэффициент ассиметрии), Kurtosis (Выборочный коэффициент эксцесса). После всех операций нажмите кнопку OK (Summary). Вы увидите таблицу со всеми выбранными значениями.
Графическое представление данных. Создайте таблицу:
| Год | Количество | |
В меню Graphs (Графики) выбрать 2М графики (2D Graphs) – Диаграмма рассеивания (Scatterplots). Если выбрать Linear fit (Подгонка) данные выстроятся относительно прямой. Тип графика Regular. Нажмите на кнопку Переменные (Variables) и выберите слева «Год», а справа «Количество». ОК. Получим диаграмму рассеивания.
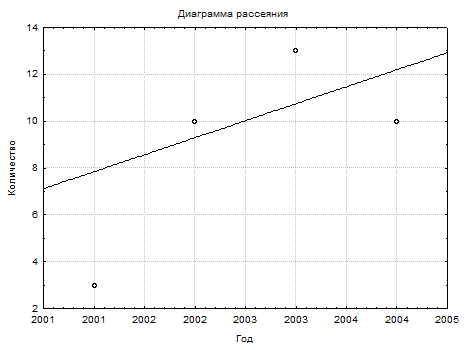
Выполните графическое представление переменных. Постройте: диаграмму рассеивания (с выравниванием и без выравнивания), гистограмму (для Переменной 1 с выравниванием и без, Переменной 2 с выравниванием и без), круговую диаграмму, двухмерную гистограмму (Bivariate Histogram).
Параметрические критерии. Наиболее часто используется t -критерий известный также как критерий Стьюдента. Проиллюстрируем его расчёт на примере из типового файла Statistica. Откройте файл Adstudy.sta. Допустим нас интересует вопрос: «различается ли восприятие напитков Pepsi и Cola мужчинами и женщинами»?
Запускаем модуль Основные статистики и таблицы (Basic Statistics/Tables). Находим строку «t-test, independent, by group». ОК. Зависимые (dependent) переменные: MEASURE01-MEASURE23, группирующая – GENDER. Ориентировочным является построение диаграмм размаха и категоризированных гистограмм.
Самым простым способом изучения таблицы является просмотр столбца с p -значениями. Здесь ищем те значения, которые меньше установленного уровня значимости (0,05 – обычный в биологии). В данном случае это MEASURE07.

В качестве примеров используйте типовые файлы: Textbooks.sta, Sonar.sta (группирующая NNST или TARGET), Random.sta (кроме столбца CATEGORY), Nonlinpca.sta, Hurrdata.sta, Activities.sta.
Непараметрические критерии. Расчёт непараметрических критериев представлен отдельным модулем Nonparametrics (Непараметрические критерии).

Отметим наличие коэффициентов ранговой корреляции. Самостоятельно вычислите тау-Кендела и ро-Спирмена для рассмотренного выше примера. Ответы должны совпасть.
Критерий Вальда-Вольфовица применятся для проверки гипотезы, утверждающей, что две группы переменных представляют собой две случайные выборки из одной генеральной совокупности. Каждой группе присваивается код, а результаты наблюдений с присвоенными им кодами называются последовательностью кодов. Например, в последовательности 010001111100 выделяют 5 серий: (0), (1), (000), (11111), (00).
Рассмотрим пример. При изучении иностранного языка в двух группах студентов использовались различные методики. После изучения курса они написали диктант. Количество ошибок равно соответственно: в первой группе – 31, 26, 33, 11, 13, 5, 18, 1, 2, 16, 17, 23, 20, 20, 21, 9, а во второй – 12, 7, 4, 8, 3, 6, 10, 25, 22, 24, 15, 19, 14, 36, 34, 32, 27,29, 30, 35, 28. Можно ли считать, что разница в методиках не влияет на результаты диктанта?
Ставим нулевую гипотезу о том, что обе выборки получены из одной генеральной совокупности. Присвоим первой группе код – 1, а второй код – 0, упорядочим выборки в порядке возрастания. Далее ищем в модуле с непараметрическими критериями строку «comparing two independent samples». В появившемся окне нажимаем кнопку Variables, где под зависимой переменной понимаются данные выборки, а под группирующей соответствующие коды.
После выполнения процедуры в результирующей таблице получим: No. of runs (число серий) = 22; No. of ties (число совпадающих значений) = 0. Определяющим является значение параметра Z, который приближается к нормальному распределению если нулевая гипотеза верна (Z = 1,2185).
Критерий Краскела-Уоллиса служит для проверки гипотезы о том, что k выборок разных объёмов были получены из одной генеральной совокупности. В модуле непараметрических критериев выберите строчку «comparing multiple independent samples (groups)». Задайте зависимую и независимую переменные (в качестве примера используйте типовой файл Kruskal.sta. Зависимая переменная здесь – PERFRMNC, независимая - CONDITN), задайте коды для групп. Вспомогательными являются диаграммы размаха и категоризированные гистограммы.
Нажимаем кнопку Summary и получаем данные. Потом переключаемся на таблицу критерия Краскела-Уоллиса. Определяющим здесь является H -критерий, который сравнивается с квантилем распределения хи-квадрат и в случае когда  гипотеза отклоняется.
гипотеза отклоняется.
Оцените нулевую гипотезу самостоятельно (для данного случая табличное значение хи-квадрат (4-1) равно 7,81).
Q-критерий Кохрена применяется только для бинарных данных (принимающих только два возможных значения). Рассмотрим пример. Для оценки четырёх видов мороженного ряду испытуемых предложили его продегустировать и дать бинарную оценку («нравится» или «не нравится», которую мы обозначим в виде «1» и «0» соответственно). Данные представим данные в виде таблицы.
Проверим нулевую гипотезу о том, что все виды продукта нравятся покупателям в равной степени. Рассчитаем Q-критерий Кохрена (модуль «Cochran Q test»). В таблице результатов даны суммы для каждой переменной, а также процент нулей и единиц. Сравниваем Q-критерий с хи-квадрат (табличное значение то же, что и в предыдущем случае). Если  гипотеза отклоняется. В нашем случае Q = 7,142857, т.е. гипотеза принимается.
гипотеза отклоняется. В нашем случае Q = 7,142857, т.е. гипотеза принимается.
| Пломбир | Эскимо | С шоколадом | С фруктами |
Дисперсионный анализ (ANOVA). Отметим, что зачастую первичный материал необходимо адаптировать под программу, т.е. перевести первичные данные в форму понятную программе. Рассмотрим пример. Пакеты с удобрениями (30 шт) распределены согласно различным условиям хранения (3 вида). После хранения в течение месяца содержание в них равно соответственно:
| Условия хранения | Содержание влаги |
| 10,1; 7,3; 5,6; 6,2; 8,4; 8,0; 7,6; 5,3; 7,2 | |
| 11,7; 12,2; 11,8; 7,8; 8,9; 8,9; 12,4; 11,0; 10,3; 13,8; 10,5; 9,8; 9,1 | |
| 10,2; 12,0; 8,8; 8,7; 10,5; 11,0; 9,1 |
Преобразуем таблицу, присвоив каждому элементу ряда код соответствующей строки. В модуле Statistics запустить модуль Основные статистики и таблицы (Basic Statistics/Tables). ОК. Здесь выберите модуль Breakdown and one-way ANOVA (Однофакторный дисперсионный анализ). Задаём Variables (Переменные) – зависимыми переменными будут значения, а группирующими коды строк. Задайте коды строк. Для получения таблицы дисперсионного анализа нажмите на кнопку Analysis of Variance.
Обозначения следующие:
§ SS Effect – мера факториальной изменчивости;
§ df Effect – число степеней свободы факториальной изменчивости;
§ MS Effect – дисперсия факториальной изменчивости;
§ SS Error – мера остаточной изменчивости;
§ df Error – число степеней свободы остаточной изменчивости;
§ MS Error – дисперсия остаточной изменчивости;
§ F – критерий Фишера;
§ p – уровень значимости.
Вычисленный уровень значимости меньше заданного, следовательно, гипотезу о равенстве средних отвергаем. Вывод – условия хранения продукта значимо влияют на влажность.

Для таблицы из лабораторной работы №2 проведите анализ и сравните с ранее полученными вами результатами.
Регрессионный анализ. В пакете Statistica для регрессионного анализа используется модуль Multiple Regression (Множественная регрессия). Рассмотрим пример расчёта модели регрессионного анализа. Дано:
| Примеси | Октановое число |
| 96,3 | |
| 95,7 | |
| 99,9 | |
| 99,4 | |
| 95,1 | |
| 97,8 | |
| 99,3 | |
| 104,9 |
Требуется определить наличие связи между наличием примесей и октановым числом бензина. Выберите модуль Multiple Regression (Множественная Регрессия). Задаём переменные: зависимая переменная – октановое число. Нажимаем кнопку ОК. Получаем результаты:

§ Dependent (Зависимая переменная).В нашем случае «октановое число».
§ No. of Cases (Число наблюдений). Здесь равно 8.
§ Multiple R (Коэффициент множественной корреляции). В случае просто линейной регрессии равен коэффициенту корреляции Пирсона.
§ R2 (Квадрат коэффициента множественной корреляции). Также известен как коэффициент детерминации. Показывает долю общего разброса (относительно выборочного среднего зависимой переменной), которая объясняется построенной регрессией (изменяется от 0 до 1).
В нашем случае равен 0,7134337, т.е. построенная регрессия объясняет более 71% разброса значений переменной «Октановое число».
§ Adjusted R2 (Скорректированный коэффициент детерминации).
 ,
,
где n – число наблюдений в модели; p – число параметров модели (число независимых переменных +1, т.к. в модель включён свободный член регрессии).
§ Standard error of estimate (Стандартная ошибка оценки). Определяется как среднее квадратическое отклонение ошибок наблюдений.
§ Intercept (Оценка свободного члена регрессии), т.е. значение коэффициента b0 в уравнении регрессии.
§ Std. Error (Стандартная ошибки свободного члена).
Если p < α (0,05), то нулевая гипотеза отклоняется (наш случай, т.к. p = 0,008315), а если p > α (0,05), то соответственно гипотеза принимается. Следовательно, в нашем случае значение b0 является достоверным. Если выбрать «Summary: Regression results», то можно также увидеть дополнительно другие значимые коэффициенты регрессионной модели.

Для оценки адекватности модели также требуется проанализировать значение F -критерия (критерий Фишера) и рассчитанный для него p -критерий. В нашем случае критерий Фишера равен F(1,6)=14,938 на уровне значимости p < 0,0083. Значения весьма значимы и следовательно нулевая гипотеза об отсутствии линейной зависимости (b1 = 0) между переменными отвергается. Модель простой линейной регрессии в этом случае принимает следующий вид:
 .
.
По этой модели легко спрогнозировать значение октанового числа при добавлении различных примесей.
Самостоятельная работа. На основании данных нижеприведенной таблицы произведите полную процедуру регрессионного анализа. Температура всегда зависимая переменная, независимые переменные меняются (исследуйте все варианты).
Таблица 3.4
Поиск по сайту: