АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Сжатие информации. Словарно-ориентированные алгоритмы (LZ77, LZSS)
Методы Шеннона-Фэно, Хаффмена и арифметическое кодирование обобщающе называются статистическими методами. Словарные алгоритмы носят более практичный характер. Их частое преимущество перед статистическими теоретически объясняется тем, что они позволяют кодировать последовательности символов разной длины. Неадаптивные статистические алгоритмы тоже можно использовать для таких последовательностей, но в этом случае их реализация становится весьма ресурсоемкой.
Алгоритм LZ77 был опубликован в 1977 г. Разработан израильскими математиками Якобом Зивом (Ziv) и Авраамом Лемпелом (Lempel). Многие программы сжатия информации используют ту или иную модификацию LZ77. Одной из причин популярности алгоритмов LZ является их исключительная простота при высокой эффективности сжатия.
Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой строки символов в сообщении заменяются ссылками на ее первое вхождение.
LZ77 использует уже просмотренную часть сообщения как словарь. Чтобы добиться сжатия, он пытается заменить очередной фрагмент сообщения на указатель в содержимое словаря.
LZ77 использует "скользящее" по сообщению окно, разделенное на две неравные части. Первая, большая по размеру, включает уже просмотренную часть сообщения. Вторая, намного меньшая, является буфером, содержащим еще незакодированные символы входного потока. Обычно размер окна составляет несколько килобайт, а размер буфера - не более ста байт. Алгоритм пытается найти в словаре (большей части окна) фрагмент, совпадающий с содержимым буфера.
Алгоритм LZ77 выдает коды, состоящие из трех элементов:
· смещение в словаре относительно его начала подстроки, совпадающей с началом содержимого буфера;
· длина этой подстроки;
· первый символ буфера, следующий за подстрокой.
Декодирование кодов LZ77 проще их получения, т.к. не нужно осуществлять поиск в словаре.
Недостатки LZ77:
· с ростом размеров словаря скорость работы алгоритма-кодера пропорционально замедляется;
· кодирование одиночных символов очень неэффективно.
Кодирование одиночных символов можно сделать эффективным, отказавшись от ненужной ссылки на словарь для них. Кроме того, в некоторые модификации LZ77 для повышения степени сжатия добавляется возможность для кодирования идущих подряд одинаковых символов.
Длина кода вычисляется следующим образом: длина подстроки не может быть больше размера буфера, а смещение не может быть больше размера словаря –1. Следовательно, длина двоичного кода смещения будет округленным в большую сторону n=log2(размер словаря), а длина двоичного кода для длины подстроки будет округленным в большую сторону m=log2(размер буфера+1). Каждый символ кодируется 8 битами (например, ASCII+). Т.е., для кодирования каждой подстроки исходного сообщения нужно n+m+8 бит.
Пример: Закодировать сообщение «Иванов Иван Иванович» с помощью метода LZ77 с размеров буфера и словаря 8 и 5 символов соответственно.
| Словарь (8) | Буфер (5) | Код | |||||||||||
| И | В | А | Н | О | <0,0,’И’> | ||||||||
| И | В | А | Н | О | В | <0,0,’В’> | |||||||
| И | В | А | Н | О | В | _ | <0,0,’А’> | ||||||
| И | В | А | Н | О | В | _ | И | <0,0,’Н’> | |||||
| И | В | А | Н | О | В | _ | И | В | <0,0,’О’> | ||||
| И | В | А | Н | О | В | _ | И | В | А | <4,1,’_’> | |||
| И | В | А | Н | О | В | _ | И | В | А | Н | _ | <1,4,’_’> | |
| О | В | _ | И | В | А | Н | _ | И | В | А | Н | О | <3,4,’О’> |
| А | Н | _ | И | В | А | Н | О | В | И | Ч | <4,1,’И’> | ||
| _ | И | В | А | Н | О | В | И | Ч | <0,0,’Ч’> |
Длина исходного сообщения: 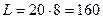 бит
бит
Длина закодированного сообщения: 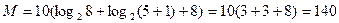 бит
бит
% сжатия: 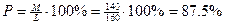
Алгоритм LZSS
В 1982 г. Сторером (Storer) и Шиманским (Szimanski) на базе LZ77 был разработан алгоритм LZSS, который отличается от LZ77 производимыми кодами.
Код, выдаваемый LZSS, начинается с однобитного префикса, различающего собственно код от незакодированного символа. Код состоит из пары: смещение и длина, такими же как и для LZ77. В LZSS окно сдвигается ровно на длину найденной подстроки или на 1, если не найдено вхождение подстроки из буфера в словарь. Длина подстроки в LZSS всегда больше нуля, поэтому длина двоичного кода для длины подстроки - это округленный до большего целого двоичный логарифм от длины буфера.
Длина кода вычисляется следующим образом: длина подстроки не может быть больше размера буфера, а смещение не может быть больше размера словаря –1. Следовательно, длина двоичного кода смещения будет округленным в большую сторону n=log2(размер словаря), а длина двоичного кода для длины подстроки будет округленным в большую сторону m=log2(размер буфера). Каждый символ кодируется 8 битами (например, ASCII+). Т.е., для кодирования каждой подстроки исходного сообщения нужно n+m+8 бит.
Пример: Закодировать сообщение «Иванов Иван Иванович» с помощью метода LZSS с размеров буфера и словаря 8 и 5 символов соответственно.
| Словарь (8) | Буфер (5) | Код | |||||||||||
| И | В | А | Н | О | 0 ’И’ | ||||||||
| И | В | А | Н | О | В | 0 ’В’ | |||||||
| И | В | А | Н | О | В | _ | 0 ’А’ | ||||||
| И | В | А | Н | О | В | _ | И | 0 ’Н’ | |||||
| И | В | А | Н | О | В | _ | И | В | 0 ’О’ | ||||
| И | В | А | Н | О | В | _ | И | В | А | 1 <4,1> | |||
| И | В | А | Н | О | В | _ | И | В | А | Н | 0 ’_’ | ||
| И | В | А | Н | О | В | _ | И | В | А | Н | _ | 1 <1,4> | |
| Н | О | В | _ | И | В | А | Н | _ | И | В | А | Н | 1 <3,5> |
| В | А | Н | _ | И | В | А | Н | О | В | И | Ч | 0 ’О’ | |
| А | Н | _ | И | В | А | Н | О | В | И | Ч | 1 <4,1> | ||
| Н | _ | И | В | А | Н | О | В | И | Ч | 1 <2,1> | |||
| _ | И | В | А | Н | О | В | И | Ч | 0 ‘Ч’ |
Длина исходного сообщения: бит
Длина закодированного сообщения: 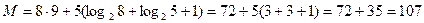 бит
бит
% сжатия: 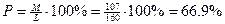
Задание:
1. Закодировать строку, состоящую из фамилии, имени, отчества, образованных от фамилии. Длину буфера и словаря подобрать так, чтобы кодирование было эффективным. Вычислить длину исходного сообщения и длину кода в битах. Вычислить процент сжатия.
ЛИТЕРАТУРА
CОДЕРЖАНИЕ
| Введение………………………………………………………………… Лабораторная работа №1. Решение систем линейных уравнений….. Лабораторная работа №2. Статистическое моделирование…………. Лабораторная работа №3. Локальная интерполяция………………… Лабораторная работа №4. Аппроксимация…………………………... Лабораторная работа №5. Решение дифференциальных уравнений и систем…………………………………………………………………. Лабораторная работа №6. Применение метода Монте-Карло для вычисления кратных интегралов……………………………………… Лабораторная работа №7. Решение задач линейного программирования……………………………………………………… Лабораторная работа №8. Синтез ПИД-регулятора…………………. Литература………………………………………………………………. |
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к лабораторным работам по курсу
«Компьютерное моделирование процессов и систем»
для студентов специальности 091400
«Системы управления и автоматики»
Составители: Береговых Юрий Владимирович, к.т.н., доц.
Бардакова Антонина Владимировна, ст. 5 курса ф-та АСУ
Грынь Ольга Викторовна, ст. 5 курса ф-та АСУ
Поиск по сайту: