АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Сжатие информации. Арифметическое кодирование
Алгоритм кодирования Хаффмена, в лучшем случае, не может передавать на каждый символ сообщения менее одного бита информации. Предположим, известно, что в сообщении, состоящем из нулей и единиц, единицы встречаются в 10 раз чаще нулей. При кодировании методом Хаффмена и на 0 и на 1 придется тратить не менее одного бита. Но энтропия д.с.в., генерирующей такие сообщения ≈0.469 бит/сим. Неблочный метод Хаффмена дает для минимального среднего количества бит на один символ сообщения значение 1 бит. Хотелось бы иметь такую схему кодирования, которая позволяла бы кодировать некоторые символы менее чем одним битом. Одной из лучших среди таких схем является арифметическое кодирование, разработанное в 70-х годах XX века.
По исходному распределению вероятностей для выбранной для кодирования д.с.в. строится таблица, состоящая из пересекающихся только в граничных точках отрезков для каждого из значений этой д.с.в.; объединение этих отрезков должно образовывать отрезок [0;1], а их длины должны быть пропорциональны вероятностям соответствующих значений д.с.в. Алгоритм кодирования заключается в построении отрезка, однозначно определяющего данную последовательность значений д.с.в. Затем для построенного отрезка находится число, принадлежащее его внутренней части и равное целому числу, деленному на минимально возможную положительную целую степень двойки. Это число и будет кодом для рассматриваемой последовательности. Все возможные конкретные коды – это числа строго большие нуля и строго меньшие одного, поэтому можно отбрасывать лидирующий ноль и десятичную точку, но нужен еще один специальный код-маркер, сигнализирующий о конце сообщения. Отрезки строятся так. Если имеется отрезок для сообщения длины n-1, то для построения отрезка для сообщения длины n, разбиваем его на столько же частей, сколько значений имеет рассматриваемая д.с.в. Это разбиение делается совершенно также как и самое первое (с сохранением порядка). Затем выбирается из полученных отрезков тот, который соответствует заданной конкретной последовательности длины n.
Принципиальное отличие этого кодирования от рассмотренных ранее методов в его непрерывности, т.е. в ненужности блокирования. Код здесь строится не для отдельных значений д.с.в. или их групп фиксированного размера, а для всего предшествующего сообщения в целом. Эффективность арифметического кодирования растет с ростом длины сжимаемого сообщения (для кодирования Хаффмена или Шеннона-Фэно этого не происходит). Хотя арифметическое кодирование дает обычно лучшее сжатие, чем кодирование Хаффмена, оно пока используется на практике сравнительно редко, т.к. оно появилось гораздо позже и требует больших вычислительных ресурсов.
При сжатии заданных данных все рассмотренные методы требуют двух проходов. Первый для сбора частот символов, используемых как приближенные значения вероятностей символов, и второй для собственно сжатия.
Пример: Закодировать сообщение «Ив» (вероятности появления символов взять из словосочетания «Иванов Иван Иванович» и распределить пропорционально)
1. Вычисляем количество символов в сообщении (без учета пробелов) и частоту каждого символа.
| И | В | А | Н | О | Ч |
Для нашего случая получаем таблицу:
L=2.
| И | В |
| 4/9 | 5/9 |

2. Упорядочиваем символы по частоте появления в тексте по убыванию: В – И.
3. Сопоставим каждому символу отрезок соответственно вероятности его появления:
| Символ | Вероятность | Отрезок |
| В | 5/9 | [0; 5/9] |
| И | 4/9 | [5/9; 1] |
4. Заполняем таблицу построения кодов: подбираем отрезки, описывающие данную последовательность символов, и соответствующее ей число, равное целому числу, деленному на минимально возможную положительную целую степень двойки
| Последовательность символов | Вероятность | Отрезок | Число, код |
| В | – | [0; 5/9] | – |
| ВВ | 25/81 | [0;25/81] | 1/4 = 0.01(2), код 01 |
| ВИ | 20/81 | [25/81; 5/9] | 1/2 = 0.1(2), код 1 |
| И | – | [5/9; 1] | – |
| ИВ | 20/81 | [5/9; 65/81] | 3/4 = 0.11(2), код 11 |
| ИИ | 16/81 | [65/81; 1] | 7/8 = 0.111(2), код 111 |
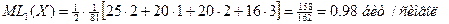 - средняя длина кода
- средняя длина кода
Среднее количество бит на единицу сообщения для арифметического кодирования получилось меньше, чем энтропия. Это связано с тем, что в рассмотренной простейшей схеме кодирования, не описан код-маркер конца сообщения, введение которого неминуемо сделает это среднее количество бит большим энтропии.
Задание: Закодировать две первых буквы своей фамилии (частоты символов распределить как в примере) с помощью арифметического метода кодирования. Вычислить среднюю длину кода. Вычислить энтропию исходного текста.
Поиск по сайту: