АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Сжатие и распаковка информации по методу Шеннона-Фано
Относится к статистическим (вероятностным) методам. Имеет две разновидности:
– статический; – динамический.
Статический предусматривает (вне зависим. от V сжимаемого документа или файла) использование априорной информации о вероятностных свойствах всех символов алфавита, на основе кот. м. б. создан произвольный документ. Символы этого документа сортируются в порядке убывания вероятности. Отсортированный массив символов исходного алфавита заменен бинарными последовательностями различной длины. Эти бинарные последовательности замещают каждый символ сж. текста и, наоборот, при распаковке. Т. о. важная задача – генерация (выработка) бинар. посл-ти.
Алгоритм генерации последовательностей (прямое преобразование) заключается в замене каждого символа соответствующим бинарным кодом:
1. Весь массив делится на 2 подмассива таким образом, чтобы сумма вероятностей в каждом подмассиве имела наименьшую разность. Каждому из символов обоих подмассивов приписываются старшие символы бинарного кода: 1 – первый подмассив, 0 – второй.
2. Делению подвергается каждый из подмассивов с приписыванием очередных символов бинарного кода, как и на предыдущем шаге. Деление продолжается до тех пор, пока каждый из конечных подмассивов не будет содержать только 1 символ алфавита.
Пример: 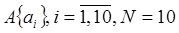

| Сортировка | ||||||

|
| |||||

| 
| |||||

| 
| |||||

|
| |||||
|
| 
| |||||
|
| 
| |||||
|
|
| |||||

|
| |||||
|
| 
| |||||
|
|
|
Как видно символам с наименьшей вероятностью соответствуют коды наибольшей длины, а с наибольшей вероятностью – наименьшие.
Сформированные бинарные коды должны отвечать следующим условиям:
1) все коды должны быть уникальными;
2) должно выполняться свойство префикса: ни один произвольный код меньшей длины не может быть началом произвольного кода большей длины.
Как видно, могут существовать различные (равнозначные) варианты разделения массива. Различные разделения будут соответствовать различные варианты кодов. Наилучший из возможных является тот вариант, которому соответствует наименьшее значение интегрального коэффициента С:
 , где
, где  – вероятн. в соотв. с таблицей; li – длина кода.
– вероятн. в соотв. с таблицей; li – длина кода.
Коэффициент С показывает среднее кол-во bit в сформировавшихся бинар. последовательностях, приходящихся на один символ алфавита А.
Алгоритм обратного преобразования (распаковки) наоборот, т.е. компрессор и декомпрессор должны пользоваться одинаковой таблицей код-символов и наоборот.
В этом процессе на выходе должны быть символы сообщения на основе исходного алфавита А. при этом важны два параметра: lmin, lmax.
Первый шаг: анализируется lmin первых символов в последовательности Yn2 на предмет их соответствия каких-либо из комбинаций в таблице. Если соответствие найдено, то на выходе преобразователя будет символ аi. Если не найдено – второй шаг: кол-во анализируемых символов увеличивается на 1 и выполняется процедура первого шага. Если на каком-либо шаге находится соответствие, то анализу подвергаются следующая lmin символов. Если ни на каком из шагов не найдено соответствие, то производится анализ последовательности: lmin+ (i -1) = lmax. Если на этом i -том шаге не найдено соответствие, то либо работа преобразования закончена и принято решение, либо принято какое-либо другое решение.
Динамический метод или адаптивный метод: частота появления символов все время меняется и по мере считывания нового блока данных происходит перерасчет начальных значений частот.
Статические методы характеризуются хорошим быстродействием и не требуют значительных ресурсов оперативной памяти. Они нашли широкое применение в многочисленных программах-архиваторах, например ARC, PKZIP и др., но для сжатия передаваемых модемами данных используются редко — предпочтение отдается арифметическому кодированию и методу словарей, обеспечивающим большую степень сжатия.
Поиск по сайту: