АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Дисперсії яких відомі (великі незалежні вибірки)
Нехай  і
і 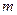 об’єми великих
об’єми великих  незалежних вибірок, для яких знайдені відповідні вибіркові середні
незалежних вибірок, для яких знайдені відповідні вибіркові середні  та
та  . Генеральні дисперсії
. Генеральні дисперсії  ,
,  відомі.
відомі.
Правило 1. Для того, щоб при заданому рівні значимості перевірити нульову гіпотезу  про рівність математичних сподівань (генеральних середніх) двох нормальних генеральних сукупностей з відомими дисперсіями (у випадку великих вибірок) при конкуруючій гіпотезі
про рівність математичних сподівань (генеральних середніх) двох нормальних генеральних сукупностей з відомими дисперсіями (у випадку великих вибірок) при конкуруючій гіпотезі  , потрібно порахувати спостережуване значення критерію
, потрібно порахувати спостережуване значення критерію
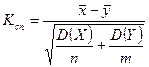 ,
,
і по таблиці 2 функції Лапласа знайти критичну точку  з рівності
з рівності
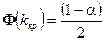 .
.
Якщо 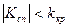 - нема підстави відкидати нульову гіпотезу. Якщо
- нема підстави відкидати нульову гіпотезу. Якщо 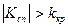 - нульова гіпотеза відкидається.
- нульова гіпотеза відкидається.
Правило 2. При конкуруючій гіпотезі  знаходять критичну точку по таблиці 2 з рівності
знаходять критичну точку по таблиці 2 з рівності
 .
.
Якщо  - нема підстави відкидати нульову гіпотезу, якщо ж
- нема підстави відкидати нульову гіпотезу, якщо ж  - нульова гіпотеза відкидається.
- нульова гіпотеза відкидається.
Правило 3. При конкуруючій гіпотезі  знаходять точку за правилом 2. Якщо
знаходять точку за правилом 2. Якщо  - нульова гіпотеза приймається, а якщо
- нульова гіпотеза приймається, а якщо  - нульова гіпотеза відкидається.
- нульова гіпотеза відкидається.
Приклад 1. За двома незалежними вибірками, об’єми яких  , вибраних з нормальних генеральних сукупностей, знайдемо
, вибраних з нормальних генеральних сукупностей, знайдемо  і
і  . Генеральні дисперсії відомі:
. Генеральні дисперсії відомі:  ,
,  . Потрібно при рівні значимості
. Потрібно при рівні значимості 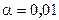 перевірити нульову гіпотезу при .
перевірити нульову гіпотезу при .
Рішення. Знайдемо 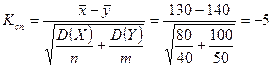 . Так як , то критична область двостороння. Знайдемо з рівності
. Так як , то критична область двостороння. Знайдемо з рівності  , тобто згідно табл.2
, тобто згідно табл.2  . Так як
. Так як 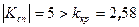 , то нульова гіпотеза відкидається, тобто генеральні середні різніться суттєво.
, то нульова гіпотеза відкидається, тобто генеральні середні різніться суттєво.
Лекція 10. КОРЕЛЯЦІЙНИЙ І РЕГРЕСІЙНИЙ АНАЛІЗ
В багатьох задачах потрібно встановити залежність випадкової величини Y від однієї чи декількох інших величин. Залежності між величинами можна поділити на функціональні і статистичні. В природничих, технічних науках здебільшого зустрічаються функціональні залежності, при яких кожному значенню аргументу х за певним законом відповідає зазвичай одне значення функції y.
Строга функціональна залежність здійснюється рідко, так як обидві величини х та y, чи одна з них підпадає під дію випадкових впливів (факторів), причому деякі з них можуть бути спільними для обох величин х та y.
Між змінними, що характеризують економічні величини, здебільшого існують залежності, які проявляються в тому, що одна з них реагує на зміну іншої зміною свого закону розподілу. Наприклад, урожайність сільськогосподарських культур залежить від кількості внесеного добрива, але ця залежність не буде функціональна, оскільки на врожайність, крім того, впливатимуть кліматичні умови, технологія землі та посіву тощо.
Статистичною називають залежність, при якій зміна однієї з величин веде до зміни розподілу іншої, зокрема кореляційним називається зв’язок між статистичними змінними Х і Y, за якими при зміні ознаки Х змінюється середнє значення ознаки Y. Причому при кореляційній залежності одному значенню незалежної змінної Х відповідає не одна, а декілька значень залежної змінної Y. Наведений приклад показує, що середня врожайність є функцією від кількості внесеного добрива, тобто Y зв’язаний з Х кореляційною залежністю.
Отже, дві випадкові величини X і Y не є незалежними, то вони називаються залежними випадковими величинами. При цьому залежність між величинами Х і Y не є, взагалі кажучи, функціональною і носить ймовірносний (стохастичний) характер. Така ймовірність вивчається методами теорії ймовірності і математичної статистики. Вивченню статистичної залежності випадкових величин і присвячений цей розділ.
§ 1. Рівняння парної регресії
В ролі оцінки умовних математичних сподівань беруть умовні середні, які знаходять за даними вибірки.
Умовною середньою  називають середнє арифметичне із значень Y, що відповідають одному і тому ж значенню Х=х.
називають середнє арифметичне із значень Y, що відповідають одному і тому ж значенню Х=х.
Приклад 1. Нехай Х – статистична величина, що характеризує вагу людини в кг, а Y – відповідно зріст в см, і двовимірний статистичний розподіл задається таблицею:
| Y | x | |||
| 70 | 75 | 80 | n | |
| 170 | 15 | 10 | 5 | 30 |
| 175 | - | 10 | - | 10 |
| 180 | - | 5 | 5 | 10 |
| n | 15 | 25 | 10 | 50 |
Наприклад, вазі 75 кг відповідає середній зріст:
 см.
см.
Аналогічно вводиться умовна середня 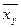 .
.
Використовуючи поняття умовної середньої, введемо таке означення кореляційної залежності.
Кореляційною називається залежність умовної середньої від аргументів і записується в такому вигляді:  , якщо n змінних:
, якщо n змінних:  .
.
Дані рівняння називають вибірковими рівняннями регресії Y на Х; функцію  - вибірковою регресією Y на Х, а її графік – вибірковою лінією регресії Y на Х.
- вибірковою регресією Y на Х, а її графік – вибірковою лінією регресії Y на Х.
Рівняння регресії найчастіше використовують як різновид статистичних моделей, що застосовують, наприклад, в економічному аналізі, де за допомогою рівнянь регресії є можливість виміряти вплив окремих факторів-аргументів на залежну змінну. Цим самим аналіз стає конкретним і цінність його суттєво збільшується. Крім регресивного аналізу, рівняння регресії використовують у прогнозних дослідженнях. В економічних дослідженнях кореляційні дослідження ввійшли під поняттям виробничі функції.
Найпростішою буде кореляційна залежність, коли є один аргумент і вона називається парною. Якщо ж аргументів більше, ніж один, то залежність називається множинною.
Вигляд рівняння визначає тип кореляційної залежності. Найбільш поширеним і простим є рівняння лінійної регресії, коли всі параметри входять в першій степені:
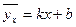 . (1)
. (1)
Прикладами можуть бути: залежність між витратами на рекламу та обсягом реалізованої продукції, витратами на споживання та валовим національним продуктом (ВНП), зміною ВНП в залежності від часу і т.д.
В загальному вигляді проста лінійна вибіркова регресійна модель запишеться так:
 . (2)
. (2)
Спочатку вважаємо, що різні значення х ознаки Х і відповідні їм значення y ознаки Y спостерігались по одному разу, тому нема потреби групувати дані, а також використовувати поняття умовної середньої, тому шукане рівняння (2) можна записати:
 , (3)
, (3)
де y – вектор спостережень за залежною змінною  ,
,
х – це вектор спостережень за незалежною змінною  , k,b – невідомі параметри регресійної моделі,
, k,b – невідомі параметри регресійної моделі,  - вектор випадкових величин (помилок)
- вектор випадкових величин (помилок)  .
.
Модель (3) можна трактувати як пряму на площині, де b – перетин її з віссю ординат, k – кутовий коефіцієнт нахилу (звичайно, якщо абстрагуватись від випадкової величини е).
Щоб мати явний вигляд залежності, необхідно знайти (оцінити) невідомі параметри k,b цієї моделі. Як це зробити, яким критерієм користуватись? Щоб відповісти на ці запитання, розглянемо приклад.
Приклад 2. Бюро економічного аналізу кондитерської фабрики оцінює ефективність відділу маркетингу з продажу цукерок. Для такої оцінки вимагає досвід роботи у п’яти зонах з майже однаковими умовами. У цих зонах зафіксовано протягом певного періоду обсяги продажі (млн. коробок), витрати (млн. грн.) фірми та рух товару на ринку (дані наведені в таблиці).
| Зони | yi 
| xi |
Візуально можна припустити, що між даними є лінійна залежність, тобто її можна наближено зобразити прямою лінією. Взагалі, існує необмежена кількість прямих y=kx+b, які можна провести через множину точок спостережень. Яку з них вибрати? Щоб це визначити, потрібно мати у розпорядженні певний критерій, що дозволяв би вибрати з множини прямих “найкращу” з точки зору даного критерію. Найпоширенішим є критерій мінімізації суми квадратів відхилень. На рис. 1 видно, що на цих прямих є точки, розташовані таким чином, що деякі з них знаходяться вище, деякі нижче цієї прямої, на основі чого можна встановити відхилення (помилки) відносно цієї прямої:

 , (4)
, (4)
де  - і -та точка на прямій, яка відповідає значенню
- і -та точка на прямій, яка відповідає значенню 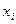 .
.
Реальні спостереження (Хі,Yі) зобразимо в системі (ХОY).

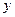
 60
60
45
35
30
25
0 5 6 9 12 18 x
Відхилення або помилки ще називають залишками. Логічно, що треба проводити пряму таким чином, щоб сума квадратів помилок була мінімальною. В цьому і полягає критерій суми найменших квадратів: невідомі параметри k та b визначають так, щоб мінімізувати  , тобто:
, тобто:
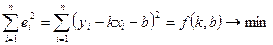 . (5)
. (5)
Мінімум функції 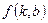 досягається за необхідних умов, коли перші похідні дорівнюють нулеві, тобто:
досягається за необхідних умов, коли перші похідні дорівнюють нулеві, тобто:
 , (6)
, (6)
або отримують лінійну систему рівнянь:
 , (7)
, (7)
що називається нормальною. Розв’язують систему і знаходять невідомі параметри k,b:
 , (8)
, (8)
 . (9)
. (9)
З метою спрощення виразу для (8) чисельник і знаменник виразу помножимо на  :
:
 , (10)
, (10)
де  . Вираз (10) можна записати ще таким чином:
. Вираз (10) можна записати ще таким чином:
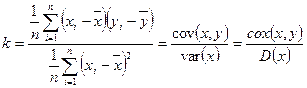 , (11)
, (11)
а розділивши друге рівняння (7) на n, отримаємо:  , звідки
, звідки  і остаточно
і остаточно  .
.
Аналогічно знаходять вибіркове рівняння прямої лінії регресії х та y:
 .
.
Приклад 3. Візьмемо дані прикладу 2 і проведемо обчислення параметрів k та b:


 .
.
Отже,  .
.
Коефіцієнт регресії k показує, на скільки зміниться детермінована складова y, якщо фактор х зміниться на одиницю.
При великому числі спостережень одне і те ж значення х може зустрітись nx раз, одне і те ж значення y-ny раз, одна пара чисел (х, y) може спостерігатись nxy раз. Тому дані спостережень групують, тобто підраховують частоти  . Всі згруповані дані заносять до так званої кореляційної таблиці:
. Всі згруповані дані заносять до так званої кореляційної таблиці:
| Y X | 
| 
| … |
| … | 
| 
|
| 
| 
| … | 
| … | 
| 
|

| 
| 
| … | 
| … | 
| 
|
| … | … | … | … | … | … | … | … |

| 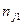
| 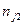
| … | 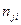
| … | 
| 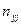
|
| … | … | … | … | … | … | … | … |

| 
| 
| … | 
| … | 
| 
|

| 
| 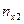
| … | 
| … | 
|
|
Тут nij – число елементів сукупності, в якій 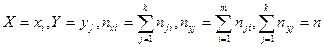 ,
,
тобто в першому рядку таблиці вказані спостережувані значення х1,х2,...хm, а в першому стовпці – спостережувані значення y1,y2,…yk. На перетині рядків і стовпців знаходяться частоти спостережуваних пар 
 .
.
Тепер повернемось до системи рівнянь (7). Використаємо тотожності
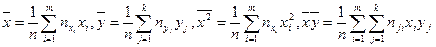 .
.
Підставивши праві частини тотожностей в систему (7), отримують систему
 , (12)
, (12)
з якої знаходять:
. (13)
Підставивши праву частину в рівняння регресії 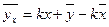 , отримують
, отримують
 , (14)
, (14)
де знову ж
 .
.
Помноживши обидві частини на  , записують:
, записують:

Підставивши rв в (14) остаточно отримаємо вибіркове рівняння прямої лінії регресії Y та Х за згрупованими даними:
 . (15)
. (15)
§ 2. Вибірковий коефіцієнт кореляції та його властивості,
методика знаходження
Число rв є вибірковим коефіцієнтом кореляції, тобто оцінкою коефіцієнта кореляції
 .
.
Сила кореляційної залежності у випадку прямої регресії оцінюється коефіцієнтом кореляції r. Так як  , то чим r ближче до
, то чим r ближче до  , тим щільніший зв’язок Y та Х, який переходить у функціональну (лінійну) залежність при
, тим щільніший зв’язок Y та Х, який переходить у функціональну (лінійну) залежність при  . Якщо r<0, то зв’язок між величинами обернений, якщо r>0, то прямий, якщо r=0, то зв’язок відсутній.
. Якщо r<0, то зв’язок між величинами обернений, якщо r>0, то прямий, якщо r=0, то зв’язок відсутній.
 Залежність щільності зв’язку між явищами від величини коефіцієнта кореляції r можна зобразити графічно.
Залежність щільності зв’язку між явищами від величини коефіцієнта кореляції r можна зобразити графічно.
1 – зв’язок тісний,
2 - зв’язок середній,
3 – зв’язок слабкий.
Вибірковий коефіцієнт rв є оцінкою коефіцієнта кореляції r генеральної сукупності і тому також служить для вимірювання лінійного зв’язку між величинами X та Y. Нехай, вибірковий коефіцієнт кореляції виявився  . Так як вибірка відібрана випадково, то звідси ще не можна робити висновок, що коефіцієнт кореляції генеральної сукупності також відмінний від нуля
. Так як вибірка відібрана випадково, то звідси ще не можна робити висновок, що коефіцієнт кореляції генеральної сукупності також відмінний від нуля  . Виникає необхідність перевірити гіпотезу про значимість вибіркового коефіцієнту кореляції (або про рівність нулеві коефіцієнта генеральної сукупності H0: r=0). Перевірку цієї гіпотези теж можна здійснити (див. [3]).
. Виникає необхідність перевірити гіпотезу про значимість вибіркового коефіцієнту кореляції (або про рівність нулеві коефіцієнта генеральної сукупності H0: r=0). Перевірку цієї гіпотези теж можна здійснити (див. [3]).
Якщо вибірка має досить великий об’єм і добре представляє генеральну сукупність, то висновок про щільність лінійної залежності між ознаками, отриманий по даних вибірки, в певній мірі може бути поширений і на генеральну сукупність. Наприклад, для оцінки коефіцієнту кореляції r нормально розподіленої сукупності (при  ), можна користуватись формулою
), можна користуватись формулою
 .
.
Нехай потрібно за даними кореляційної таблиці обчислити вибірковий коефіцієнт кореляції. Розрахунки можна спростити, якщо перейти до умовних варіант (при цьому величина rв не зміниться)
 ,
,
де ui, vj – умовні варіанти, с1, с2 – хибні нулі, тобто варіанти, що мають найбільшу частоту, h1, h2 – кроки, тобто різниці між будь-якими двома сусідніми варіантами.
Тоді:
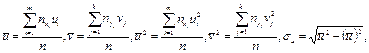
 .
.
Оскільки при знаходженні rв вже обчислені  , то доцільно повернутись до величин х, y:
, то доцільно повернутись до величин х, y:
 .
.
І записати рівняння лінійної регресії:
 .
.
Приклад 1. Зв’язок ознак Х та Y подається кореляційною таблицею:
| Y X |
| ||||||
| - | - | - | - | ||||
| - | - | - | - | ||||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | |||||
|
|
Записати рівняння прямої регресії.
Рішення. Переходимо до умовних варіант  , тобто С1=45, С2=38, h1=5, h2=10 (С1, С2 – варіанти, що мають найбільшу частоту 35).
, тобто С1=45, С2=38, h1=5, h2=10 (С1, С2 – варіанти, що мають найбільшу частоту 35).
| V U | -3 | -2 | -1 | 
| |||
| -2 | - | - | - | - | |||
| -1 | - | - | - | - | |||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | |||||

|
Послідовно знаходимо:

 ;
;
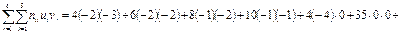
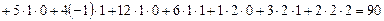 ;
;
 ;
;  ;
;  ;
;
 .
.
Рівняння прямої регресії Y та Х має вигляд:
 або
або  .
.
Лекція 11. БАГАТОФАКТОРНА ТА НЕЛІНІЙНА РЕГРЕСІЯ
Поиск по сайту: