АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомДругоеЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция
Эконометрические модели
Инструментом для создания таких моделей является корреляционно-регрессионный анализ случайных величин.
Использование на практике эконометрических моделей предполагает, что соответствующая система имеет достаточно жесткую структуру. Описываемые этой моделью процессы характеризуются стабильностью.
Разработка таких моделей является довольно трудоемким и сложным делом. Поэтому всегда следует вначале решить вопрос о целесообразности разработки эконометрической модели, сопоставив затраты на ее разработку с экономическим эффектом от ее использования. В качестве альтернативного варианта может быть выбран вариант использования экспертных методов прогнозирования.
Эконометрическая модель может быть описана системой регрессионных уравнений следующего вида:
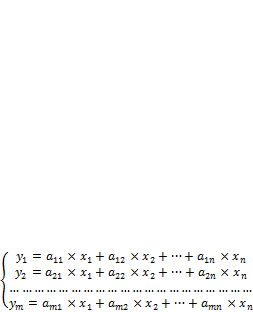 (2.2.28)
(2.2.28)
Здесь  – зависимые (эндогенные) переменные, a
– зависимые (эндогенные) переменные, a  – независимые (экзогенные) переменные.
– независимые (экзогенные) переменные.
Частным случаем эконометрических моделей регрессионные модели.
Этот тип моделей широко используется в прогнозировании экономических характеристик. Однако следует иметь в виду, что в инновационной сфере возможности применения регрессионных моделей существенно ограничены. Так же как и экстраполяционные методы, регрессионные модели могут быть использованы лишь в комплексе с другими, более гибкими, методами прогнозирования.
Если трендовые модели отражают зависимость исследуемой характеристики только от времени, то создание регрессионных моделей базируется на том, что существует ряд факторов, влияющих на данную характеристику. Причем, учет этого влияния поддается формализации.
В общем случае регрессионная модель имеет вид:
 , (2.2.29)
, (2.2.29)
где  - неслучайная составляющая исследуемой характеристики (зависимая переменная);
- неслучайная составляющая исследуемой характеристики (зависимая переменная);
xi — i-й фактор (независимая переменная), i = 1 - п.
Разработка модели осуществляется в 3 этапа:
♦ спецификация;
♦ оценивание параметров;
♦ анализ качества.
Спецификация модели заключается в решении двух основных задач:
♦ выявление факторов, влияющих на исследуемую характеристику;
♦ определение формы уравнения регрессии.
Решение этих задач основано на глубоком качественном анализе проблемы с учетом статистических данных. На этапе спецификации оно носит лишь предварительный характер. Окончательное решение эти задачи получают в результате дополнительных исследований с использованием математического аппарата корреляционно-регрессионного анализа на следующих этапах разработки модели.
Рассмотрим решение задачи по оцениванию параметров модели на примере уравнения парной линейной регрессии:  .
.
Исходными данными для построения модели являются две совокупности наблюдений:
1. - значения независимого факторах.
2. - значения зависимого фактора у, зафиксированные при соответствующих значениях х. Линия регрессии описывает изменение неслучайной составляющей характеристики у. Для любого значения i = 1, 2,..., n значение у можно представить в следующем виде:
 , (2.2.30)
, (2.2.30)
где  — соответствующее значение неслучайной составляющей; еi - i-я реализация случайной составляющей.
— соответствующее значение неслучайной составляющей; еi - i-я реализация случайной составляющей.
Дальнейшие построения, по сути, ничем не отличаются от построений, использованных нами при оценивании параметров линейного тренда. Те же требования предъявляются к случайной составляющей и к оценкам параметров уравнения. Для получения этих оценок используют метод наименьших квадратов.
В общем случае исследуемая характеристика у может зависеть от нескольких факторов. Тогда регрессионная модель называется моделью множественной регрессии.
На практике чаще всего пользуются моделями линейной регрессии:
 . (2.2.31)
. (2.2.31)
Построение модели линейной множественной регрессии производится аналогично модели парной линейной регрессии, только при этом используется матричная форма записи. Параметры {аг} оценивают по методу наименьших квадратов.
Нелинейные регрессионные модели легко могут быть преобразованы к линейному виду с помощью несложных приемов линеаризации. После этого, оценивание параметров производится так же, как для линейной модели, а затем модель вновь преобразуется к исходному виду.
Рассмотрим процедуру анализа качества регрессионной модели.
Уточним вначале, что, говоря о качестве регрессионной модели, мы будем иметь в виду модель множественной линейной регрессии.
Поскольку на практике процедуры построения моделей осуществляются с помощью специальных статистических пакетов прикладных программ для ЭВМ, то проблемы оценивания параметров, анализа качества и уточнения формы модели решаются параллельно.
Анализ качества модели заключается в выполнении следующих задач:
♦ оценка значимости коэффициентов уравнения;
♦ анализ взаимосвязей между переменными модели;
♦ оценка значимости модели в целом;
♦ исследование характеристик случайной составляющей модели.
В хорошей модели (т. е. в модели, пригодной для практического использования) все коэффициенты уравнения должны быть значимыми.
Взаимосвязи между переменными исследуют с помощью коэффициентов парной корреляции. Коэффициенты корреляции между любыми двумя факторами хi и xj (i ≠ j) должны быть незначимыми (в идеале равными нулю); в противном случае эти факторы дублируют друг друга. А коэффициенты корреляции между исследуемой характеристикой у и любым из факторов xi должны быть значимыми, иначе этот фактор не оказывает существенного влияния на результат и может быть исключен из уравнения модели.
При анализе взаимосвязей с помощью коэффициентов парной корреляции параллельно корректируется форма исходной модели. Этот процесс требует творческого подхода. Исключение отдельных факторов может улучшить одни и, одновременно, ухудшить другие показатели качества модели. Поэтому исследователь должен, зачастую, идти путем проб и ошибок, перебирая и анализируя различные варианты моделей.
Значимость регрессионной модели в целом оценивается с помощью трех показателей:
♦ коэффициентом множественной корреляции;
♦ коэффициентом детерминации;
♦ критерием Фишера.
Все эти показатели могут с одинаковым успехом быть использованы для оценки значимости регрессионной модели. Однако если модель нелинейна, то следует использовать критерий Фишера.
Случайная составляющая модели оценивается остатками {еi}, где:
Процедура анализа остатков регрессионной модели аналогична соответствующей процедуре для анализа трендовой модели. Единственное отличие состоит в том, что при проверке на отсутствие автокорреляции остатки предварительно необходимо расположить в хронологической последовательности.
Напомним, что в хорошей модели случайная составляющая должна подчиняться нормальному закону распределения вероятностей с нулевым математическим ожиданием, постоянной дисперсией и отсутствием автокорреляции между любыми двумя соседними значениями.
Допустим, что мы смогли построить несколько моделей, удовлетворяющих всем, рассмотренным выше показателям качества:
♦ все коэффициенты уравнения значимы;
♦ модель в целом значима;
♦ выполняются все требования к случайной составляющей.
Тогда возникает вопрос, какая из построенных моделей самая лучшая? С формальной точки зрения наилучшей моделью следует считать модель с максимальным значением критерия Фишера, рассчитанного для оценки значимости модели в целом.
Для линейных регрессионных моделей стой же целью можно использовать коэффициент детерминации или коэффициент множественной корреляции, а для нелинейных - сумму квадратов остатков. Однако, наилучшая модель, выбранная по критерию Фишера, будет наилучшей и по всем другим перечисленным критериям.
Прогнозирование с использованием регрессионных моделей осуществляется следующим образом.
На первом шаге определяются прогнозные значения факторов на момент времени t: {x1p, x2p, …, xnp}.
При нормативном прогнозировании это могут быть плановые значения. В других случаях значения факторов могут быть оценены, например, экспертным методом или с помощью соответствующих трендовых моделей.
На втором шаге прогнозные значения факторов подставляют в регрессии. Таким образом, рассчитывают среднее значение прогноза исследуемой характеристики на момент времени tp-yp.
На третьем шаге рассчитывается доверительный интервал прогноза  с выбранной доверительной вероятностью Рдов.
с выбранной доверительной вероятностью Рдов.
Например, для модели парной линейной регрессии доверительный интервал прогноза на момент времени tp может быть рассчитан по формуле:
 , (2.2.32)
, (2.2.32)
где S- среднеквадратическое отклонение остатков;
 р - значение, рассчитанное по уравнению тренда;
р - значение, рассчитанное по уравнению тренда;
ta — значение t-критерия Стьюдента, выбранное из таблицы для доверительной вероятности и числа степеней свободы v-п-2;
хр - прогнозное значение фактора;
n - количество наблюдений.
Чем сильнее хр отличается от среднего значения фактора хср, тем шире доверительный интервал прогноза.
Поиск по сайту: